Interpolated SLMs
This topic describes interpolated SLMs and shows several ways to create them.
An interpolated SLM is a probabilistic SLM made up of two or more SLMs. Depending on the type of smoothing method chosen (interpolated or slm+backoff), these component SLMs can be assigned weights that reflect their contribution to the recognition process.
For example, if SLM_1 is given a weight of .1 (10%) and SLM_2 a weight of .9 (90%), then the probabilities for words given by SLM_2 are more powerful and drive the recognition.
Say that SLM_1 has a probability of 0.5 for the words “my house” and SLM_2 a probability of 0.1 for the same words. Even though the word probability is lower in SLM_2, assigning more weight to SLM_2 (.9) says that this SLM is considered more reliable in a real-world situation and provides better results.
By using a combination of specific attributes in the SLM source code, you can create three different types of interpolated SLMs:
|
Interpolated SLM type |
Created by |
|---|---|
|
log-linear |
smoothing="interpolated" and combine="log" (log is the default) |
|
linear |
smoothing="interpolated" and combine="linear" |
|
slm+backoff |
smoothing="slm+backoff" and priority="primary|backoff" |
Optionally, you can assign weights only to log-linear and linear interpolated SLMs. You can’t with slm+backoff interpolated SLMs. Say the question is, “What is the probability for the words, ‘my father plays hockey.’” The primary SLM is asked first. If this SLM doesn’t have the probability, then the backoff SLM is asked. If the primary SLM has the probability, the backoff is not used.
Why use interpolated SLMs
Here are some reasons for using interpolated SLMs:
- Not enough data: An SLM for a particular domain might be incomplete. The vocabulary reflects the domain (for example, medical terms) but isn’t trained with enough data to give a high degree of recognition accuracy. This SLM can be combined with a larger SLM that is well-trained but doesn’t reflect the current domain. Initially, the incomplete SLM is assigned a low weight and the larger SLM is assigned a high weight. As you get more data and better train the in-domain SLM, you can adjust the interpolation weights accordingly. As your confidence grows, you can assign a higher weight to the in-domain SLM relative to the out-of-domain SLM.
- Training: Each of the component SLMs are trained on data from different sources. As each of these sources improves, the individual SLMs can be retrained without needing to include data from all sources. Additionally, the new SLM can be weighted more strongly to reflect the fact that the SLM is considered to be more accurate.
- Application focus: An application might expect a specific type of utterance such as a date but also want to allow a more generic utterance. In this case, the application could use a grammar that has a strong date language model combined with one that has a general natural-language model.
- User-specific information: An application may need to add user-specific information to a more general SLM, such as an address book SLM interpolated with a generic SLM.
Restrictions
Note these restrictions for the component SLMs that are used to create an interpolated SLM:
- Component SLMs compiled prior to v10.2.4 must be recompiled before using them in an interpolated SLM. An error occurs if you don’t.
- The component SLMs in an interpolated SLM must be the same type: either all log-linear, all log, or all slm+backoff. An error occurs if you mix them.
- Component SLMs can be referenced only once. An error occurs if you reference a component more than once when creating an interpolated SLM.
This example shows a hierarchical structure consisting of three interpolated SLMs. Because it is more complex, it could happen that you inadvertently use the same component more than once. Note that the top-level interpolated SLM, vm, contains two components, lm1 and lm2. However, lm1 references an interpolated SLM that contains two components, one of them being lm2. This causes an error as lm2 is named as a component of both interpolated SLMs.
...
<slm id="vm" smoothing="interpolated" combine="linear">
<component uri="#lm1" type="application/x-vnd.nuance.slm+xml" weight="0.9"/>
<component uri="#lm2" weight="0.1"/>
</slm>
<slm id="lm1" smoothing="interpolated" combine="linear">
<component uri="slm_2.xlm" weight="0.9"/>
<component uri="#lm2" weight="0.1"/>
</slm>
<slm id="lm2" smoothing="interpolated" combine="linear">
<component uri="slm_3.xlm" weight="0.9"/>
<component uri="slm_4.xml" weight="0.1"/>
...
- The default combine method is log interpolation If you’re combining linear SLMs, you must set the combine attribute to linear (
smoothing="interpolation" combine="linear"). If you’re combining linear SLMs and don’t declare all of them explicitly as linear, an error will occur. - Nuance recommends you combine no more than three SLMs in one interpolated SLM.
SLM document types
Language model components can be stored either in a source or in a compiled form with the following media types:
- For the source form: application/x-vnd.nuance.slm+xml
- For the compiled form: application/x-vnd.nuance.slm
The source form typically has the extension slmxml, and the compiled form the extension slm.
Additionally, an SLM component can be specified in terms of the Nuance Recognizer slm-training-file format. In that case, Recognizer compiles the file into an SLM in-line.
Source SLM format
This section describes the elements and attributes for creating the source file for an interpolated SLM.
The <language_model> element has these attributes:
- root: Defines the document root.
- version: Must be 1.0.
- xmlns: Declares the namespace. Must be http://www.nuance.com/slm.
The <slm> element has these attributes:
- id: Name by which the component is referenced. Required.
- smoothing: Values are interpolated or slm+backoff:
- Interpolated: A form of averaging multiple SLMs.
- slm+backoff: First consults the primary SLM. If no match is found, consults the backoff SLM.
You must specify the smoothing attribute when merging two or more component SLMs. If you don’t, the SLM component can be only a single SLM reference, without a weight, offset, or priority.
- combine: Used only when
smoothing="interpolated". Valid values are linear or log. Default is log. You cannot mix combine methods in an interpolated language model. The component SLMs must be all log or all linear.
The <component> element has these attributes:
- uri: Either an external or internal reference. An external reference must reference one of the document types declared in SLM document types.
- weight: Component weight. Used only when
smoothing="interpolated". Default is 1.0. For linear interpolation (combine="linear"), all weights must be >= 0. Generally, ensure the sum of all weights equals 1.When using weights, you must distinguish between linear and log interpolation. For linear interpolation, the resulting probability is:
P_linear = w_1 * P_1 + w_2 * P_2
For log interpolation, the resulting probability is:
ln(P_log) = w_1 * ln(P_1) + w_2 * ln(P_2)
P_1 and P_2 are the probabilities given by the two combined SLMs and w_1, w_2 are the weights used to combine them.
Note: Remember, you cannot combine linear and log component SLMs in an interpolated SLM. The component SLMs must be all log or all linear.
- offset: Offset for smoothing. Used only when the smoothing attribute is set to interpolated and the combine attribute is set to log (default).
The interpolated probability is computed as weight*logprob+offset. Default value is 0.0.
- type: Media type of SLM for an external reference. Media types conform to SLM document types. If a type is not explicitly declared, it is determined by inspecting the contents of the document.
Referencing a source SLM document type can cause increased memory and CPU usage when the interpolated SLM is built. Nuance recommends you precompile source SLMs before using them as component SLMs.
- priority: Valid values are primary or backoff. Used only when the smoothing attribute is set to slm+backoff. Only a single primary and a single backoff are allowed.
Remember that you cannot mix interpolated SLM types. If you are using
smoothing="slm+backoff", you cannot have any component SLM that has declaredsmoothing="interpolated". - binding: Valid values are static or dynamic. A static reference is bound at compile time. Dynamic binding is dereferenced at activate time. The default is static.
Note that dynamically bound components:
- Are cached separately and shared across all referencing grammars
- Undergo HTTP updates independently
External targets of dynamic URIs cannot contain dynamically bound components.
As noted, certain attributes can be used only in combination with others. This table summarizes these combinations:
|
smoothing |
combine |
weight |
offset |
priority |
|---|---|---|---|---|
|
Not explicitly set |
Not used |
Not used |
Not used |
Not used |
|
interpolated |
Used (default = log) |
Used |
Used (only if combine = log) |
Not used |
|
slm+backoff |
Not used |
Not used |
Not used |
Used |
Examples
This section shows code snippets to create log, linear, and slm+backoff interpolated SLMs.
This example creates an interpolated language model using two log component SLMS. The default combine method is log, so you don’t have to set this attribute.
<?xml version="1.0" encoding="ISO-8859-1"?>
<language_model root="SLM_12" version="1.0" xmlns="http://www.nuance.com/slm">
<slm id="SLM_12" smoothing="interpolated">
<component uri="slm_1.xml" weight="0.2"/>
<component uri="slm_2.xml" weight="0.8"/>
</slm>
</language_model>
This example creates an interpolated language model using two linear component SLMS. Since the default combine method is log, you must set the combine attribute to linear.
<?xml version="1.0" encoding="ISO-8859-1"?>
<language_model root="SLM_12" version="1.0" xmlns="http://www.nuance.com/slm">
<slm id="SLM_12" smoothing="interpolated" combine="linear">
<component uri="slm_1.xml" weight="0.2"/>
<component uri="slm_2.xml" weight="0.8"/>
</slm>
</language_model>
This example creates an interpolated language model using two component SLMs, a primary and a backoff:
<?xml version="1.0" encoding="ISO-8859-1"?>
<language_model root="SLM_12" version="1.0" xmlns="http://www.nuance.com/slm">
<slm id="SLM_12" smoothing="slm+backoff">
<component uri="slm_1.xml" priority="primary"/>
<component uri="slm_2.xml" priority="backoff"/>
</slm>
</language_model>
Hierarchical interpolated SLMs
A hierarchical interpolated SLM is a tree structure which specifies how to combine the probabilities of two or more component SLMs to obtain a better suited probability. For example:
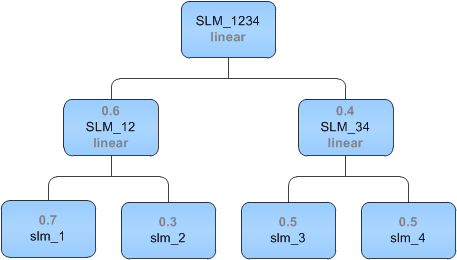
Each node shows a parent-child relationship. The lowest level contains the simplest component SLMs. These are combined and weighted using linear interpolation (smoothing="interpolation" combine="linear") to create the two parents, SLM_12 and SLM_34. These in turn are combined to create the root parent, SLM_1234.
The final probability of the hierarchical SLM is obtained by the root element (SLM_1234), which consists of probabilities and weights determined by all the parents and children:
P_1234 = 0.6* P_12 + 0.4*P_34 = 0.6* (0.7*p_1 + 0.3*p_2) + 0.4*(0.5*p_3 + 0.5*p_4)
This next example shows a hierarchical structure using the slm+backoff method. The backoff method estimates the probability of a word given its history in the n-gram. It accomplishes this estimation by “backing off” to other language models to provide, if possible, a higher-order n-gram probability.
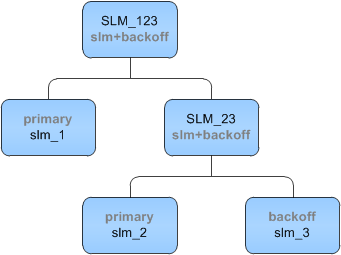
This diagram says, “Try to get the higher ordered n-gram probability from slm_1. If slm_1 doesn’t give an estimate, then instead of using the unigram probability from slm_1, try to get the higher-ordered probability from slm_2. If slm_2 also doesn’t give an estimate, try (back off to) slm_3.
Here is the code to create this hierarchy:
<?xml version="1.0" encoding="ISO-8859-1"?>
<language_model root="SLM_123" version="1.0" xmlns="http://www.nuance.com/slm">
<slm id="SLM_123" smoothing="slm+backoff">
<component uri="slm_1.xml" priority="primary"/>
<component uri="#SLM_23" priority="backoff"/>
</slm>
<slm id="SLM_23" smoothing="slm+backoff">
<component uri="slm_2.xml" priority="primary"/>
<component uri="slm_3.xml" priority="backoff"/>
</slm>
</language_model>
Declaring SLMs in a grammar
SLM documents are declared in the context of a grammar. For example:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<grammar version="1.0" xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en-us" mode="voice">
<language_model root="root" version="1.0" xmlns="http://www.nuance.com/slm">
<!--collection of <slm> blocks-->
</language_model>
...
</grammar>
Simple
The simplest SLM declaration contains only one SLM component. This can be an interpolated SLM or a simple SLM. The declaration might look something like this:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<grammar version="1.0" xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en-us" mode="voice">
<meta name=’swirec_fsm_parser’ content=’NULL’/>
<language_model root="root" version="1.0" xmlns="http://www.nuance.com/slm">
<slm id="root">
<!--statically linked -->
<component uri="./my.slm"/>
</slm>
</language_model>
...
</grammar>
More complex
A more complex SLM declaration contains two or more component SLMs. These components can be interpolated or simple SLMs. The declaration might look something like this:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<grammar version="1.0" xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en-us" mode="voice">
<meta name=’swirec_fsm_parser’ content=’NULL’/>
<language_model root="root" version="1.0" xmlns="http://www.nuance.com/slm">
<slm id="root" smoothing="interpolated" combine="linear">
<component uri="./my.slm" weight="0.7"/>
<component uri="./medical_jargon.slm" weight="0.3">
</slm>
</language_model>
...
</grammar>
With SSM
If you add a Statistical Semantic Model (SSM) interpreter to the simple SLM, you might have:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<grammar version="1.0" xmlns="http://www.w3.org/2001/06/grammar"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2001/06/grammar
http://www.w3.org/TR/speech-grammar/grammar.xsd"
xml:lang="en-us" mode="voice">
<meta name=’swirec_fsm_parser’ content=’NULL’/>
<language_model root="root" version="1.0" xmlns="http://www.nuance.com/slm">
<!--Default SLM is interpolated with a component weight of 1.0 -->
<slm id="root">
<!--statically linked -->
<component uri="./my.slm" type="application/x-vnd.nuance.slm"/>
</slm>
</language_model>
<semantic_interpretation xmlns="http://www.nuance.com/semantics">
<component confidence_threshold="0.33">
<interpreter uri="interpret.ssm" type="application/x-vnd.nuance.ssm"/>
</component>
</semantic_interpretation>
...
</grammar>
Creating a binary SLM file
You can use sgc to generate a binary output SLM with the new argument -slm. Input can be an SLM training file or an slmxml file. For example:
> sgc –slm mytraining.xml
This command generates the SLM mytraining.slm.
Compiling grammars
You can use the sgc utility to precompile or dynamically compile a grammar that contains a <language_model> specification. All statically-bound language-model components are loaded into the resulting binary file.
Any valid SRGS grammar can reference a properly formed SLM training grammar or binary SLM grammar.
Dynamically-bound components are not dereferenced until grammar activation. As described above, these components are cached separately and, if appropriate, are refreshed according to standard HTTP semantics.
Limitations
Because of the special nature of SLM-type grammars in the system, there are some limitations with respect to SLMs that reference ordinary grammars and ordinary grammars that reference SLMs.
Rule references ("ruleref") in SLM vocabulary
SLM components that are dynamically bound (binding = dynamic) into a grammar cannot use rulerefs in their vocabulary.
Compilation optimization requirements
Grammars built with a <language_model> section are compiled using optimization level 11. This means that any grammars these grammars reference (using rulerefs in the vocabulary) must also be compiled with optimization 11 (or for source grammars, have a <meta> specifying optimization 11). The reverse is also true: a grammar that imports an SLM-type grammar must be built using optimization 11 (or have the appropriate <meta>).
