Tuning SLMs
Once deployed, an application can always be improved and fine-tuned. For SLMs in particular, real-life call data can be used to improve the training set used to generate the SLM. You can do several iterations to fine-tune an SLM.
Note: Deploy all voice applications in gradual phases so you can correct mistakes and tune while there few users and reduced system loads.
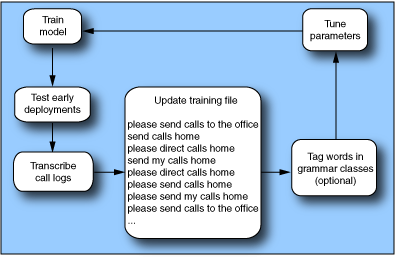
The steps in the tuning process are:
- Begin with the initially trained model.
- Exercise the compiled model (runtime recognition) as early as possible during the application development lifecycle. These early phases of the lifecycle include usability testing, pre-deployment (the first weeks of low-load usage), and full deployment (the first months of increasing load).
- At runtime, Recognizer produces call logs and audio waveforms. Use these to transcribe caller utterances and produce new sentences to be included in the next training file.
- Optionally, tag words that belong to common groups (for example, phrases for speaking dates). See Extending SLMs with grammar classes.
- Refine configuration parameter settings. See Tuning perplexity.
- With the additional sentences added, recompile the training file. The result is a new, compiled model that can be used for the next iteration of the process. You can repeat the entire process several times, as recognition accuracy improves with each iteration.
- Optionally, create an additional set of test sentences as an evaluation set. The purpose of the evaluation set is to provide an independent validation of trained and tuned models. Do not use these sentences for tuning iterations. Instead, keep them separate until the tuning is nearly complete.
Tuning perplexity
The true measure of effectiveness is recognition accuracy; but an easier-to-compute measure for tuning an SLM is test set perplexity.
Perplexity is closely related to the average sentence score achieved on a set of test sentences. To compute perplexity:
- Generate the SLM.
- Create a test set file, with one test sentence per line.
- The set of sentences in the file must not be the same as those used for training the SLM. However, in both sets, the distribution of the sentences must reflect the actual distribution of sentences seen in the application.
Submit the compiled grammar and test set to the parseTool or sgc utilities, and inspect the results.
As an example, consider the following parseTool command:
parseTool sample.gram -compute_lm -perplexity test_sentences.txt
The tool writes a line similar to the following to standard error:
Perplexity = 37.23
Here’s a sample sgc command with the -test option to measure perplexity:
sgc -train sample.xml -test test_sentences.txt
High perplexity implies that recognition will be difficult, while low perplexity indicates a greater likelihood of accurate recognition. As you vary SLM parameters, try to achieve the lowest possible perplexity for the same test set. For details on the training file parameters, see the section about the SLM training file header.
Modifying training file parameters
Tuning an SLM involves modifying the training file parameters and assessing the resulting accuracy. As you make changes, there will be fluctuations in CPU and memory usage at runtime: monitor resource usage and balance any accuracy improvements with optimum resource allocation.
Parameter complexity
Parameter complexity is a measure of how noticeable and predictable a change in the parameter is in its affect on the SLM. In general, parameters have one of the following three complexities:
- Basic parameters have a predictable effect on the system behavior. Tune these first, and resolve any issues with the default settings.
- Intermediate parameters affect more subtle behavior of the system. These parameters may be more difficult to measure, and have an effect on the accuracy of the application. Change these only when it is possible to do sufficient analysis and testing.
- Advanced parameters are the last resort for addressing problems with the default parameter. They may exhibit subtle effects on other parts of the system. Tune them cautiously with extensive testing and analysis.
Commonly modified parameters
The following table lists the most commonly modified training file parameters, and describes factors that might lead you to increase or decrease their value, or to enable or disable that parameter altogether.
|
Name |
Complexity |
Increase (or set to 1 if Boolean) if... |
|---|---|---|
|
cutoffs |
Medium |
You need to cut down size/computing of model—a large .gram file produced by sgc is a clue that the model is big. This may lead to lower SLM accuracy. For details, see cutoffs. |
|
ngram_order |
Medium |
You have a large amount of training data. For details, see ngram_order. |
|
swirec_lmweight |
Advanced |
You want Recognizer to emphasize language model evidence over acoustic evidence. Set this parameter in The <meta> element of the training file. This parameter interacts with pruning during recognition, so it must be thoroughly tested with recognition of speech utterances. |
|
swirec_max_arcs |
Advanced |
You want to prevent excessive searching caused by non-speech noise on the audio channel. Set this parameter in The <meta> element of the training file. This parameter interacts with pruning during recognition, so it must be thoroughly tested with recognition of speech utterances. |
Setting swirec_lmweight and swirec_max_arcs in the training file doesn’t effect the training itself, but adds the values to the binary SLM output. The optimal values depend on the size of the SLM, the vocabulary, the installed language packs, and other factors. You must test accuracy and performance thoroughly. (If you train the grammar with an FSM and wordlist output, there is no binary SLM, and the values have no effect. In this case, add the values to the wrapper grammar for the FSM and wordlist.)
Use parseTool for testing, as described in Testing an SLM.
Determining the order of the model
The next step is to determine the order of the model. Is a trigram SLM better than a bigram for your application? The larger the n, the more powerful the n-gram model is, since a larger context is used to assign a probability to a word. However, the number of probabilities needed in the model grows as a power of n, and is therefore more difficult to estimate at large n values. Also, by increasing n when the training samples are limited, the model may experience over-training; that is, the model may memorize the training set and hence lose its ability to model sentences that the training set does not cover.
The optimum value of n is usually empirically determined by training a number of different n-gram SLMs and measuring their performance (at least 500 sentences are needed to get a reasonable estimate of the performance). Test set must be different from training sets, and both must reflect the actual distribution of caller sentences. You can also use perplexity measurements, as described in Tuning perplexity, to determine the value of n.
The default order for an SLM is 2. However, use 3 whenever possible. When the training set has less than 2 million words (not counting duplicate sentences), set the following parameter values in the training file:
<param name="cutoffs"><value> 0 0 </value></param>
<param name="smooth_weights">
<value> 0.1 0.9 0.9 0.9 </value></param>
<param name="smooth_alg"><value> GT-disc-int </value></param>
When the training set contains over 2 million words, discard 3-grams as follows:
- Increase the cutoffs parameters to discard at least the 3-grams that are singletons (seen only once):
<param name="cutoffs"> <value> 0 1 </value> </param>
- Add a parameter to write the SLM in the ARPA format:
<param name="print_arpa"> <value> name.arpa </value> </param>
- Train the SLM without compiling the full grammar:
sgc –train name.xml –fsm_out name.fsm –wordlist_out name.wordlist –no_gram
- Check the combined number of 2-grams and 3-grams in the ARPA output (use the command: head name.arpa). Avoid 2-grams and 3-grams that number more than 2 million. Otherwise, memory usage is too high. If there are still more than 2 million n-grams, try increasing the cutoffs and retraining the SLM (without compiling the full grammar). It is advisable to discard at least the tripleton 3-grams (seen 3 times or less) before discarding any 2-grams.
