Speech processing with VoiceXML
VoiceXML is the most common language for over-the-phone speech applications. It is a standard XML format for specifying interactive voice dialogs between a human and a computer that feature synthesized speech, digitized audio, recognition of spoken and DTMF key input, recording of spoken input, telephony, and mixed-initiative conversations. VoiceXML for voice applications is analogous to HTML for visual applications. Just as HTML documents are interpreted by a visual web browser, VoiceXML documents are interpreted by a voice browser.
Nuance does not dictate how to create and translate VoiceXML documents. Instead, the voice browser expects well-formed documents that use Nuance features:
- VoiceXML documents to be well-formed. The application development environment must create documents that conform to the specification.
- Nuance-specific configurations and capabilities to be made available to applications. Nuance products have more features than the basics covered by the VoiceXML specification.
Voice applications use VoiceXML elements, properties, and attributes to identify data to be fetched. The voice platform converts those parameters into MRCP messages, and forwards them to the Nuance Speech Server.
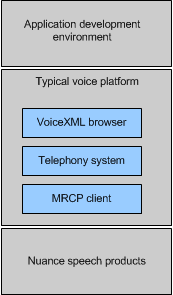
Speech Server, in turn, accesses speech recognition, meaning extraction, and/or prompt production from Nuance speech software: for example, to fetch additional resources such as grammars, language and semantic models, and possibly recognition tuning data (lexicons) from a web server, and to fetch recorded prompts and TTS tuning data (dictionaries and so on).
This architecture has a number of advantages: scalability, fault tolerance, manageability, and so on. In addition, the use of MRCP and Speech Server gives applications access to Nuance speech recognition and text-to-speech features that are not available in other systems.
