Resource manager features
The Nuance Resource Manager registers each instance of each Dragon Voice engine, and responds to application requests by allocating suitable resources for recognition and interpretation.
| Dragon Voice engine | Capabilities registered for allocation by resource manager |
|---|---|
|
Krypton recognition engine |
Language, data pack topic, and data pack version. |
|
Nuance Text Processing Engine (NTpE) |
Same as above: language including data pack topic, and data pack version. (This engine is not used or needed for Krypton-only recognition.) |
|
Natural Language Engine (NLE) |
Semantic pipeline name and version, as well as IDs of any semantic models loaded. (This engine is not used or needed for Krypton-only recognition.) |
- Nuance Resource Manager requires Apache ZooKeeper for fault tolerance and coordination of services. See Setting up ZooKeeper.
- You must run ZooKeeper before starting the Nuance Resource Manager and Dragon Voice engines. Otherwise, Management Station displays alarms as Dragon Voice engines attempt to register.
-
Never rename or move data packs after installation. Doing this causes the Krypton engine capabilities to disappear in the resource manager.
- Never replace an installed data pack with a different pack of the same (identical) name. Doing this causes unpredictable conflicts between the new pack and existing data in the memory cache.
Purpose of the resource manager
The Natural Language Processing service communicates with the Resource Manager to allocate recognition and interpretation resources based on the requested capabilities passed along by the Speech Server (from the application).
The Resource Manager in turn allocates a suitable engine resource and notifies the NLP service of the selection, prompting the NLP service to:
- For Krypton, create a session with the resource so that Krypton may fetch/load additional items such as one or more domain language models.
- For NLE, send a load request for the specified semantic model ID (concatenation of domain, project, language, and version) if it is not yet loaded. NLE will extract information from the semantic model and use this information (language, topic, and version of data pack) to request at runtime a suitable registered NTpE resource to perform the interpretation.
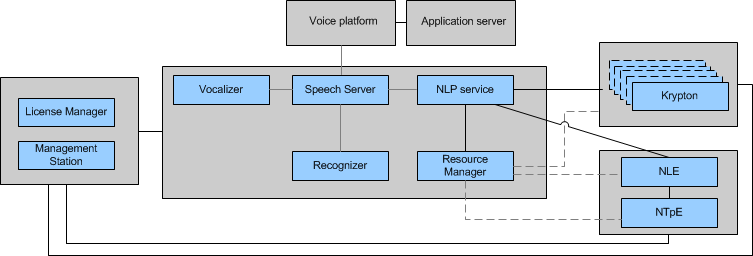
When the application indicates that all recognition/interpretation requests complete, the allocated service instances disconnect from each other: Speech Server and NLP service disconnect from Krypton and NLE, and NLE disconnects from NTpE.
Tip: For information on the format of the VoiceXML request sent by the application, see Triggering the Dragon Voice recognizer.
The resource manager uses ZooKeeper for fault tolerance
Nuance Resource Manager works with Apache ZooKeeper, which is a high-performance coordination service. ZooKeeper allows distributed processes to coordinate through a shared hierarchical namespace. For example, processes can maintain configuration, provide group services, and manage partial failures.
ZooKeeper runs in replicated mode on a cluster of hosts called an "ensemble" that ensures service so long as a quorum (a majority) of hosts are running. For example, in a three-node ensemble if one host fails, the ensemble continues with the remaining two. Similarly, in a five-node ensemble, three hosts must be running at all times.
On startup the Resource Manager registers itself with the ZooKeeper cluster, and records engine information in the ZooKeeper database.
- The first resource manager to register is the primary. It monitors engine resources, and processes requests from clients (forwarded by the Speech Server via the NLP service). To process requests the Resource Manager considers the current load (defined as the number of times the engine was allocated within a designated time window) and selects the engine with the smallest workload. This has the effect of distributing load across the engines.
- Any other resource managers are secondary. Their purpose is to provide high availability and failover capabilities. Any requests received by secondary resource managers are routed to the primary.
- If the primary resource manager fails, one of the secondaries becomes the new primary. The former primary joins the pool of secondaries when it recovers.
Tuning alarms for overloaded services
The Resource Manager estimates engine workload by counting the number of times the engine is allocated (during a configurable time window), and generates the minor alarm "An overloaded engine was allocated" when the engine is allocated too often during that window. You can use the frequency of these alarms to detect overloaded engines. For example, if an application requires a language that's only available in one instance of an engine, and the resource manager frequently generates the alarm on that instance, you might distribute the load by adding the language to additional instances.
Optionally, you can adjust the thresholds for generating the alarm on instances of the NLE and NTpE engines.
Note: This tuning changes the threshold for alarms seen by system operators. It does not affect actual system load or how the Resource Manager allocates engine instances.
Use these properties to raise or reduce the alarm threshold:
| Property | Description |
|---|---|
|
A time window used for gauging the load on an engine instance. The Resource Manager counts how many times it allocates an engine during the time period defined by this property. If the counter exceeds the overload limit, the Resource Manager generates an alarm to warn operators that system load might be too high. To avoid the alarms, consider adding new instances of the engine. |
|
|
Triggers alarms when an engine instance is too heavily loaded. The Resource Manager generates the alarms when the number of instances exceeds this number during the configured window of time. |
