Adding natural language capabilities
Natural language technologies enable grammars that extract meaning from a wide range of user utterances without explicitly defining every word that the user may say. These natural language grammars avoid complex grammar rules by deriving statistical models from from real-world data. This versatility makes natural language grammars ideal for mixed-initiative dialogs.
Natural language understanding
A natural language understanding (NLU) system invites a caller to speak a full sentence as input and returns an interpretation—a representation of the meaning of that sentence.
For example, consider the following phrases spoken to a banking application in response to an open-ended prompt (“What can I do for you today?”):
- “Transfer fifteen hundred dollars from savings to checking”
- “Take fifteen hundred out of savings, and put it in my checking account”
- “Add one thousand five hundred dollars to my checking account. Take the money from my savings.”
These responses have one meaning, but express it very differently. Regardless of what the caller says, the grammar needs to extract information into corresponding information slots:
- An action (transfer)
- An amount ($1500.00)
- A source account (savings)
- A destination account (checking)
A standard SRGS grammar would not be able to extract this information from all possible sentences. Such a grammar would have to be extensive and extremely complex in order to cover such a wide variety of sentences, and would take a great deal of CPU resources to compile and load. (Furthermore, its out-of-grammar rate could still prove unacceptably high. See Out-of-grammar solutions.)
Natural language techniques offer a better alternative. A natural language understanding engine takes the spoken sentence and returns a simple, structured interpretation of the meaning of what the caller said.
From an implementation perspective, this approach can speed development because you don’t need to account for all possible ways people will speak. You can use open-ended prompts such as “How may I help you?” in the application, and the system is able to minimize the effect of any dysfluencies (“um”, “er”, and other meaningless interjections) and extraneous words (“please”, “I would like to”), and return the essential meaning of the sentence as simple text.
From the caller’s perspective, a natural language system is convenient and quick. Callers are able to complete their tasks efficiently, supplying several pieces of information at once, without plodding through a tedious directed dialog or experiencing long pauses.
NLU techniques
Natural language techniques use actual caller speech to create statistical models that predict the patterns of speech in future calls. Since the probability assigned to each phrase depends on the context and is driven by data, a natural language grammar assigns higher probabilities to the more plausible phrases.
Within Nuance, the collection of natural language techniques is known collectively as SpeakFreely™ technology. SpeakFreely includes:
- Statistical language models (SLM): An SLM takes the results from actual caller input, and uses them to calculate the probabilities of how a future caller will answer. An SLM can function on its own as a simple recognition grammar, but is almost always used as underlying support for another technique.
- Robust parsing grammars: A robust parsing grammar is able to identify the key items within a user utterance, while ignoring any dysfluencies or filler words that carry no significant meaning. This renders it able to interpret many different sentences that mean the same thing, without having to predict every possible permutation explicitly in GrXML. It requires a supporting SLM.
- Statistical semantic models (SSM): An SSM assigns meaning to the output of an SLM, and uses the words or combinations of words appearing in a free-form utterance to determine the probable meaning. This makes an SSM useful for interpreting open-ended utterances, where the same answer can be given in many different ways without using the specific key words that a robust parsing grammar requires.
- N-grams: An N-gram model calculates the probability that a given recognized word will follow another given word(s). N-grams are automatically part of an SLM. Recognizer also supports a method of creating n-gram models independently.
These natural language features all require that you prepare a training file, an XML file which includes transcriptions of the collected user data to be used to train the feature. This training file is used to derive the statistical models.
Training sets
Any natural language approach depends on the use of a training set that consists of sentences to be covered. A useful training set will generally contain hundreds, thousands, or tens of thousands of example text utterances, depending on the complexity of the language you wish to capture and the natural language method you intend to use. See Very large training files.
These samples can be transcriptions of responses to an application designed for data collection purposes; they can be historical phrases stored in a database from some existing application; or you can invent sentences. The best data is real data from actual user responses to your application.
The sentences in your training set must be added into a training file, an XML document whose format is determined by the natural language technique you are using.
Combining natural language techniques
The figure below shows relationships among natural language technologies during recognition:
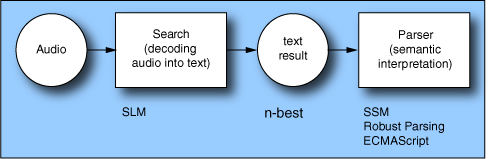
Recognizer processes the audio of caller utterances, and decodes it into text. During the decoding, Recognizer uses a statistical language model to determine the available vocabulary and the probable sequences of words, providing an n-best list. This n-best result is then processed by the SSM, robust parsing grammar, or (rarely) ECMAScript to return a semantic meaning.
CPU and memory resource usage
At runtime, advanced natural language grammars do not use more CPU and memory resources than comparable SRGS grammars. However, natural language grammars tend to be large, and to require monitoring during initial phases of deployment to ensure their efficient use.
Note: Monitor resource usage during SLM and SSM tuning. As you modify parameters in training files, there are runtime fluctuations in CPU and memory usage. Balance accuracy improvements with optimum resource allocation.
Enhancing SRGS grammars with natural language
An SRGS grammar is exact: it constrains user speech to specific words and phrases. Any words or phrases that are not included in the grammar are rejected.
One useful feature available in SRGS grammars is the ability to weight items. By definition, every SRGS grammar models the speech allowed; however, you can influence this implicit language model by assigning weights to individual grammar items, and by using scripts.
However, it is also possible to add simple natural language shortcuts and garbage phrases to SRGS grammars. These simple techniques are not able to address complex natural language needs, but on occasion they can be useful.
Out-of-grammar solutions
The common characteristics of all natural language approaches is that they address the biggest challenge to automatic speech recognition (ASR) systems: out-of-grammar errors.
Remember, most ASR systems understand humans the same way you might understand a foreign language if you were traveling. If you hear words that you recognize from a list in your trusty phrase book, then you can understand what people are saying—as long as they stick to phrases on your list. Likewise, a typical ASR system recognizes what callers say—as long as callers say things on the list of accepted responses in the grammar.
Today’s ASR systems work quite well. Ninety-eight percent accuracy is considered very good for a deployed ASR system. However, to say “the speech recognition system is 98 percent accurate” is to measure in-grammar accuracy without counting when a speaker says something that’s not on the list.
These out-of-grammar errors are three to five times more likely to be the cause of a system rejecting a caller’s response than misrecognition. The average rate at which callers say things that are not on the list, across all contexts, might be 16%, or even as high as 30%. In other words, the perceived accuracy of those systems—the accuracy that callers experience—might be as low as 70%.
Developers strive to make the grammars for ASR systems as comprehensive as a good traveler’s phrase book. They might put in more guesses as to what speakers might say. This is a useful, but partial solution. It might even provide the illusion of natural language. Faking natural language with larger grammars, however, can lower the accuracy and speed of an ASR system.
True natural language circumvents the need to anticipate everything a caller might say. Without natural language, a confused machine may reject a caller’s perfectly reasonable answer “Umm, I’d like to pay a bill please,” because it wasn’t on the list of hard-coded responses. Natural language technology helps a system better understand a human’s words because it recognizes a wider variety of responses, even if it’s never heard them before. Statistical models based on what people might say teach a system to understand the caller’s intent (Take me to the payments menu) without a developer manually predicting each variation. It’s the difference between traveling with a phrase book and being fluent in the local language.
