Controlling speech recognition and TTS
When applications use Nuance speech resources, communications must pass down and up through a multi-layer stack. The stack begins with the VoiceXML application, and continues down through the voice browser (including the MRCP client), Nuance Speech Server, and then to the individual Nuance resources.
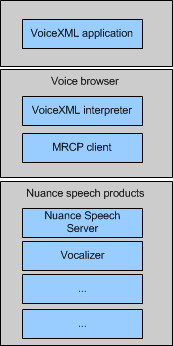
Although the application may not have direct control over lower layers of this stack, developers can be aware of defaults at those layers and decide to use non-default values.
For example, you can:
- Send speech requests over TCP or TLS (rather than via RTP).
- Deliver prompts via MRCP instead of RTP.
- For Nuance Recognizer, use different recognition modes to enable selective barge-in and magic word or to recognize plain text (retrieve documents) as an alternative to audio input, as described in Proprietary Recognizer features.
Below is a summary of the relationship among configuration parameters at different levels of the resource stack, listed in order of decreasing precedence.
- VoiceXML properties—Properties set by the VoiceXML application for a particular session or utterance. The VoiceXML 2.0 specification defines numerous properties. When the browser interprets properties on a VoiceXML page, it is responsible for setting the corresponding MRCP or vendor-specific parameters to configure Nuance components. See Speech processing with VoiceXML.
Note: An application also controls recognition with a session.xml file. See Configuring application sessions.
- MRCP—Your browser can either pass through configuration requests from the application, or use its own default values. The browser translates VoiceXML property settings to standard MRCP headers. The browser uses headers to set parameters; for example, in the RECOGNIZE or SET-PARAMS message to set recognition parameters, and in the SPEAK or SET-PARAMS message to set Vocalizer parameters. See Implementing an MRCP client.
The Nuance Speech Server software supports all MRCP recognition resources. See the MRCP recommendation.
- Recognizer and Vocalizer directly control many aspects of the recognition/speech synthesis process, if not overridden by requests from other, higher-precedence components such as Speech Server.
Notes:
- For Recognizer see Rules of parameter precedence.
Many other Recognizer parameters can be set only on the Nuance recognition service. Often, these parameters fine-tune the recognizer’s performance, and they cannot be set from the application or voice browser. For all Recognizer parameters, see the Recognizer parameter reference.
- For Vocalizer see Configuring Vocalizer as well as Vocalizer parameter reference. Many of these parameters set defaults that applications typically can override for individual sessions or synthesis requests.
- For Recognizer see Rules of parameter precedence.
