Creating SLMs
The figure below shows the process for generating an SLM from a training file. For a detailed view of process iterations, see Tuning SLMs.
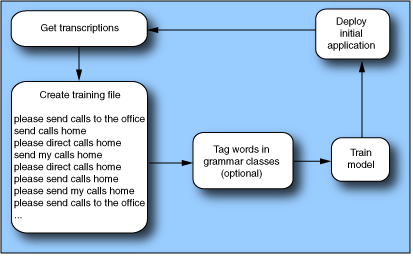
This process involves several steps:
- Create a training file of sample sentences and a vocabulary. Ideally, base them on actual data. See Data collection for training files.
- Optionally, identify and tag useful grammar classes to improve SLM accuracy. See Extending SLMs with grammar classes.
- Determine the order n of the model. The default order is 2: however, use 3 whenever possible. See Determining the order of the model.
- Generate the SLM. (See Training an SLM.) For pure language recognition and no semantic interpretation (this is not common), generate an output .gram file and use it as if it were an SRGS grammar. Otherwise, generate .fsm and .wordlist files and use the <meta> element to wrap them into a robust parsing grammar (see Robust parsing grammars) or with a statistical semantic model (see SSMs).
- Use the SLM grammar in your application, and test it during early deployment with small numbers of users. During the test, evaluate the speed and success of interactions with users, generate new transcriptions, augment the training file, and make needed changes to configuration parameters.
- If necessary, iterate this process to improve the SLM.
