Process lifecycle for SSMs
The figure below illustrates an iterative process for generating an SSM from a training file. You supply the training file, generate the SSM, and include the output in a wrapper grammar. You deploy the application gradually with tuning iterations of grammars and prompts based on real-life telephone calls.
Several steps require significant manual effort, including the creation of the training file, transcription, data tagging, and manual grammar tuning.
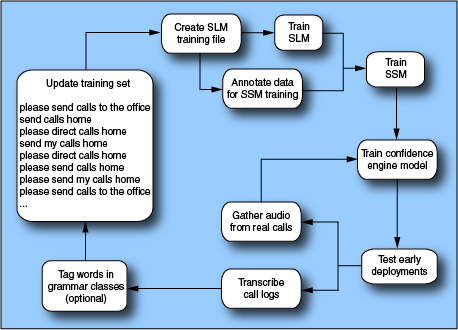
The steps in the SSM creation and tuning process are:
- Begin the process by creating initial training files. The files can initially contain utterances that are collected via a simulated applications (such as a Wizard of Oz collection): or, if you have no real data, you can instead use utterances invented by application developers (that is, "fake" data). However, this is to be avoided; real data is always preferable.
For a discussion of data collection, see Data collection for training files. For more on SSM training files, see Training files.
- Create and train an SLM from the training data.
- Generate the SSM using the ssm_train tool.
See Training an SSM.
- Generate a confidence engine model. This can be done as soon as enough data has been collected. Typically, you create a confidence engine during tuning, if it is not possible for the first iteration of the lifecycle.
- Wrap the generated SSM and confidence files in a wrapper grammar.
- At runtime, Recognizer produces call logs and audio waveforms. Use these to transcribe caller utterances, produce new sentences for the SLM and SSM training files, and new audio for the confidence engine training file.
- Refine settings of configuration parameters to improve results.
For details, see Testing and tuning SSMs.
- With the additional sentences, regenerate the SSM for the next iteration. Repeat the entire process several times as recognition accuracy improves.
- Exercise the SSM grammar (runtime recognition) as early as possible during the application development lifecycle. These early phases of the lifecycle include usability testing, pre-deployment (the first weeks of low-load usage), and full deployment (the first months of increasing load).
- Optionally, create a set of evaluation sentences. An evaluation set is an additional set of test sentences; while optional, its use is strongly recommended. The purpose of the evaluation set is to provide an independent validation of trained and tuned models. Do not use these sentences for tuning iterations. Instead, hold them aside until the tuning is nearly complete.
