Testing and tuning SSMs
You can test your SSM during and after training.
A critical component of the SSM training file is the <test> section. The sentences in that section are used to control the number of training iterations. After each iteration of training, the sentences in the <test> section are used to assess the accuracy of the current SSM. The general goal is to loop while the statistical model’s accuracy is improving, and to stop when the improvements stop.
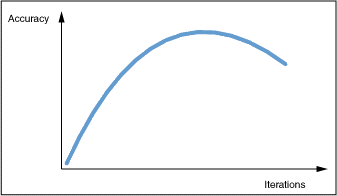
The following figure illustrates the approximate curve of improvements. Note that over-training (processing too many iterations) leads to over-fitting on the training data, which reduces the performance on the test set.
Testing guidelines
During training, the model is repeatedly, and automatically tested against the test sentences that you provide in the training file. Your primary method for improving the model at this time is with the quality and quantity of test sentences. Here are some guidelines for creating a good test set:
- The test data must be independent from the training data, but both must reflect the actual distribution that will be seen in the application. As suggested earlier, a good way to achieve this is to separate the same training set into training data and test data.
- You must have at least 500 test sentences from a real source: fake data is not acceptable for tuning purposes. If you don't have real data but you need to produce a model, then leave all parameters set to their default values, since you have no principled way to optimize the model.
- The ratio of sentences is be approximately 75% for training to 25% for testing. For example, if you have 2000 sentences, use 1500 for training and 500 for testing.
Some grammar developers prefer to verify the results of their tuning with a separate set of test sentences known as an evaluation set. In this scenario, you iteratively tune the model with the training and test sets, and then check the final results against the independent evaluation set. This practice avoids focusing the model too much on a particular test set, and prevents overly-optimistic estimate of performance. For this tuning, use approximately 60% of the sentences for training, 20% for testing, and 20% for the evaluation test.
Tuning guidelines
Tuning is the process of adjusting configuration parameters in the training file and re-training the model. Guidelines:
- The log files created during training cycles contain accuracy details. You can determine which words are training well and which are having difficulty. By comparing logs generated at different numbers of iterations, you can determine optimal amount of training.
- As you collect more real data during pilot testing and partial deployment, use the newest data for the test and evaluation sets and move previous test and evaluation data to the training set.
Related topics
Overview
Related tasks
Related topics
Using in applications (wrapper grammars)
Feature extraction and ECMAScript
Reference
