Configuration during application development
Application developers configure application sessions and individual recognition events. They use different configurations for development and deployment systems depending on the emphasis for troubleshooting, testing, tuning, or performance.
This illustration shows configuration mechanisms available to application developers:
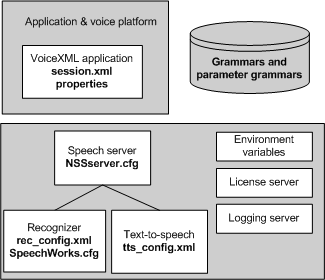
Configuration summary:
- The VoiceXML application specifies properties that the voice browser communicates to the Speech Server, Recognizer, and text-to-speech engine. The settings are often valid for a single recognition or synthesis event, whereupon they revert to their default values.
Applications specify two kinds of properties: basic properties as defined in the VoiceXML specification, and Nuance-specific parameters that refine the control of Recognizer. The browser passes the Nuance parameters as MRCP vendor-specific properties.
- The session.xml configures defaults for the duration of the session.
- Speech grammars contain parameters to control individual recognition events. Recognizer loads the settings when the application activates a grammar. Parameter grammars configure a group of active grammars.
- Management Station sets defaults for a specific recognition service instance. Application developers change parameters this way when a higher-level mechanism is not available.
- The text-to-speech capabilities of Nuance Vocalizer support parameters that may be set in Management Station.
These parameters are occasionally set differently for application development and deployment.
Setting these parameters requires access to the recognition host.
|
Parameter |
Description |
Default |
|---|---|---|
|
Application’s tagmap files for custom TRC diagnostic logging. |
(empty) |
|
|
Enables (or disables) the disk and inet caches. |
1 (enabled) |
|
|
Ignores missing pronunciations during grammar compilation. Useful for applications that automatically generate grammars (for example, generating grammars at runtime from data in a database). This parameter is not useful for hand-written grammars. |
0 (disabled) |
Applications configure Recognizer for each recognition event.
Typically, the VoiceXML application sets these parameters with a <property> tag, and the browser passes values to Speech Server in MRCP headers.
|
Parameter |
Description |
Default |
|---|---|---|
|
Allows callers to interrupt prompts. |
1 (enabled) |
|
|
How long to wait before concluding that a caller is finished speaking. |
0 (timer disabled) |
|
|
Minimum confidence score. Nuance Recognizer rejects utterances with scores below this value. (Does not apply to Dragon Voice recognition.) |
0 (all utterances accepted) |
|
|
Duration of silence to determine that callers have finished speaking. |
1500 (milliseconds) |
|
|
Maximum duration of an utterance collected from users. |
-1 (no timeout) |
|
|
Sensitivity of the speech detector when looking for speech. |
0.5 |
|
|
Sets security levels for protecting confidential data. |
open |
|
|
How long to wait for speech after a prompt ends. |
7000 (milliseconds) |
Applications use these parameters to control a grammar’s recognition results and to return special key/value pairs in the results.
Typically, the VoiceXML application sets these parameters with a <property> tag, and the browser passes values to Speech Server as MRCP vendor-specific parameters.
|
Parameter |
Description |
Default |
|---|---|---|
|
Adds grammar keys to the XML result. |
SWI_meaning, SWI_literal, SWI_grammarName |
|
|
A grammar script to be invoked on the root rule of each n-best result. |
(empty) |
|
|
A grammar script to be invoked on the root rule of each n-best result. |
(empty) |
|
|
Maximum number of n-best answers that can be returned. |
2 (n-best length) |
|
|
Adds the speech mode attribute to nomatch recognition results (to conform to VoiceXML 2.0). |
0 (disabled) |
|
| resultNbestExtraKeys | Dragon Voice: adds confidence scores to the XML result. | (empty) |
All grammar parameters can affect CPU usage, compilation or recognition latencies, and recognition accuracy. These parameters have a strong impact.
Application developers set some of these parameters using a <meta> inside grammars. Other parameters are set on the Nuance recognition service via Management Station.
|
Parameter |
Description |
Default |
|---|---|---|
|
Speeds recognition time at the cost compilation performance. |
0 (feature is off) |
|
|
Ignores missing pronunciations during grammar compilation. |
0 (disabled) |
|
|
Specifies a text file that maps language declarations in grammars to Nuance language codes. |
(Recognizer language codes) |
|
|
Number of pronunciations to generate automatically when a word is not found. |
1 (pronunciations) |
|
|
Maximum number of pronunciations per word. |
8 (pronunciations) |
|
|
Limits the number of pronunciations for phrases in user dictionaries. |
0 (pronunciations for whole phrases and their individual words) |
|
|
Improves accuracy by adding a normalized, probabilistic language model. |
0 (normalization is off) |
|
|
Optimization level for the grammar. |
6 (for dynamic compilations) |
When writing speech grammars, use the parameters shown in the sections below. Set these parameters inside grammar files using the <meta> tag. There are two general categories:
- Parameters applied to individual grammars
- Parameters applied to the set of active grammar (grammars activated in parallel).
These parameters balance compilation time, recognition time, and recognition accuracy. Typically, improving performance of one dimension decreases performance of the others:
|
Parameter |
Description |
Default |
|---|---|---|
|
Speeds recognition time at the cost compilation performance. |
0 (feature is off) |
|
|
Optimization level for the grammar. |
6 (for dynamic compilations) |
These parameters balance the variety of pronunciations with compilation time, recognition time, CPU load, and recognition accuracy:
|
Parameter |
Description |
Default |
|---|---|---|
|
Maximum number of pronunciations per word. |
8 (pronunciations) |
|
|
Limits the number of pronunciations for phrases in user dictionaries. |
0 (pronunciations for whole phrases and their individual words) |
These parameter tune application performance by controlling Recognizer’s search for matches:
|
Parameter |
Description |
Default |
|---|---|---|
|
Maximum number of nodes visited during the a-star search. |
100000 (nodes visited) |
|
|
Adds weight to match the dynamic ranges of language and acoustic models. |
1.0 |
|
|
Maximum number of active FSM arcs. |
10000, 5000, 3000 |
|
|
Provides a secondary guide to the Viterbi beam search. |
-30, -60, -60 |
|
|
Limits search paths that end in a silence model during pruning. |
56, 56, 56 |
|
|
Primary guide for the Viterbi beam search. |
0, -15, -35 |
|
|
Maximum number of n-best answers that can be returned. |
2 (n-best length) |
Semantic interpretation:
|
Parameter |
Description |
Default |
|---|---|---|
|
Maximum number of parses evaluated by Recognizer for a single literal string. |
10 (parses) |
|
|
Specifies a single key to return in the recognition result instead of all keys. |
(empty) |
|
|
Controls whether Recognizer performs word confidence calculations. |
0 (disabled) |
Nuance can provide custom models for an application, and for specific contexts within a speech grammar. These parameters control the usage of those models:
|
Parameter |
Description |
Default |
|---|---|---|
|
Points to custom models for firstpass processing in Recognizer. |
(default models are used for each language) |
|
|
Defines allophone maps for secondpass processing in Recognizer. |
(default mapfiles used) |
|
|
Defines finite state machines for secondpass processing in Recognizer. |
(default fsm files used) |
|
|
Acoustic models for secondpass processing in Recognizer. |
(default models used) |
Use these parameters when building models for SLMs and robust parsing grammars:
|
Parameter |
Description |
Default |
|---|---|---|
|
Specifies an n-gram grammar file that defines a Statistical Language Model (SLM). |
(empty) |
|
|
Specifies a finite state machine (fsm) used by a speech grammar. |
(empty) |
|
|
Specifies a wordlist used by a speech grammar. |
(empty) |
|
|
Specifies an SLM training set. |
(empty) |
These parameters are used when building SLMs, but also have other uses:
|
Parameter |
Description |
Default |
|---|---|---|
|
Temporarily stops self-learning activities for one or more languages. |
(depends on language) |
|
|
Improves accuracy by adding a normalized, probabilistic language model. |
0 (normalization is off) |
This parameter is used when building SSMs:
|
Parameter |
Description |
Default |
|---|---|---|
|
Default confidence threshold any application SSMs. |
0.0 |
These parameters control audio data after the application collects utterances from users and delivers them to Recognizer.
The VoiceXML application sets some of these parameters with a <property> tag, and the browser passes values to Speech Server as MRCP vendor-specific parameters. Other parameters are set by system administrators on the recognition host.
|
Parameter |
Description |
Default |
|---|---|---|
|
Maximum number of channels to save waveforms (recordings of speech from callers). |
-1 (no maximum) |
|
|
How much silence is kept at the start of a collected utterance. |
0 (milliseconds) |
|
|
How much silence is kept in a collected utterance. |
0 (milliseconds) |
|
|
How much silence is kept in a collected utterance. |
0 (milliseconds) |
|
|
Maximum number of channels allowed to save waveforms (recordings of speech from callers). |
-1 (no maximum) |
|
|
Removes line noise from audio recordings. |
10 (percent) |
|
|
Returns waveforms in recognition results. |
1 (enabled) |
These parameters control Recognizer data written to the call logs.
Typically, the VoiceXML application sets these parameters with a <property> tag, and the browser passes values to Speech Server as MRCP vendor-specific parameters.
|
Parameter |
Description |
Default |
|---|---|---|
|
Sets security levels for protecting confidential data. |
open |
|
|
Adds application or browser information to call logs to synchronize runtime activities with log analysis. |
(empty) |
|
|
Suppresses logging of confidential values in grammar URI strings. |
(empty) |
|
|
Number of n-best entries written to the call log. |
2 (n-best entries) |
These parameters control the magic word and selective barge-in features, which enable responses based on detecting specified words.
Typically, the VoiceXML application sets these parameters with a <property> tag, and the browser passes values to Speech Server as MRCP vendor-specific parameters.
|
Parameter |
Description |
Default |
|---|---|---|
|
Confidence threshold for magic word recognition results. |
500 |
|
|
Confidence threshold for selective_barge_in mode. |
500 |
Typically, these parameters are set for all applications running on the Speech Server host. Alternatively, browser can set these parameters with MRCP vendor-specific parameters.
|
Parameter |
Description |
Default |
|---|---|---|
|
Maximum duration of a magic word candidate for recognition. |
800 (milliseconds) |
|
|
Minimum duration of a magic word candidate for recognition. |
200 (milliseconds) |
|
|
Sets special recognition modes (such as magic word) in the endpointer. |
begin_only |
|
|
Sets special recognition modes in Recognizer. |
normal |
These parameters are for troubleshooting speech grammars. System administrators set them on the recognition host:
|
Parameter |
Description |
Default |
|---|---|---|
|
Storage location for grammars fetched by Recognizer. |
NULL (disabled) |
|
|
Maximum size of the grammar dump directory. |
100000 (100 MB) |
By default, built-in grammars use the Recognizer’s default language (which is determined during installation). When the application language does not match the default, the application must declare a language whenever it uses a built-in grammar.
