Note: The content in this topic is for Dragon Voice in on-premise deployments.
Call logs contain standard information provided by Nuance speech products plus events from these sources:
- The voice application writes custom events. See Application-defined logging events.
- The voice platform (for example, a VoiceXML browser) writes events such as start and end of calls.
Nuance offers the Nuance Insights for IVR tool to read call logs and generate reports and tuning recommendations. The tool is very useful, but is not required for reading the logs. Because the logs are text files, you can use any text editor or script to analyze the logged data.
How call logs are structured
Each line (record) of a call log file contains a series of token/value pairs that describe a single event. The lines are terminated by newline control sequences; the maximum size of a line is 10 kilobytes.
Within each record the format is:
- Event codes and tokens are separated by the "|" character.
- If there is a "|" character in data, it is quoted by inserting an additional "|" character to form the sequence "||".
- Tokens are always uppercase.
- Tokens are separated from their values by the "=" character, and a single token can have more than one "=" character.
The following is a sample log record:
TIME=20030315145902975|CHAN=1|EVNT=SWIacsv|AACC=noise.intmodels.stats.20030315145820|ADIR=c:/speechworks/baseline/acoustic_adapt|NMIN=1034|LANG=en-us|UCPU=0|SCPU=0
All time-related codes log times in millisecond units (unless specified otherwise), and are accurate to within 0.01 second.
Nuance products write log events with the uppercase SWI, KR, NLE, NUAN, or NVOC prefix followed by lowercase letters. For example, SWIrcst is the code for "Recognition Start." To avoid confusion, do not use these prefixes with any user-defined events.
Tokens used for every event
The first entries in each log record are TIME, CHAN (CHANNEL), and EVNT; the last entries are UCPU and SCPU.
|
Token |
Description |
|---|---|
|
TIME |
System time when the event occurred, in the following format (accurate to within 0.01 second): YYYYMMDDhhmmssmmm. |
|
CHAN |
A unique session identification name provided when the session is created. |
|
EVNT |
Prefix used for event codes (limited to 8 characters; longer names are truncated):
|
|
UCPU |
The current running value of "user" CPU time consumed from the start of the recognition or synthesis. This value is reported in milliseconds, accurate to within 0.01 second. |
|
SCPU |
The current running value of "system" CPU time consumed from the start of the recognition or synthesis. This value is reported in milliseconds, accurate to within 0.01 second. |
The following list shows groups of standard Speech Server event codes. Production sites might encounter additional codes and tokens not described here.
| SWIclst—call start | Indicates the beginning of a call to the system. |
| SWIclnd—call end | Indicates the end of a call to the system |
| NUANwvfm—waveform | Written whenever an utterance is written to an audio file in the call logs. |
| SWIwcr—whole call recording | Written whenever a session recording is written to an audio file in the call logs. |
| NVOCinpt—input text | Provides the input text for the speak request. |
Event records that detail recognizer executions, recognitions, special events (such as compilation and cache activities), and caller utterances. These records contain information such as:
- Timestamps of each event
- Recognition results with confidence scores
- Timing statistics of each recognition event
- Names of audio files containing caller utterances
The following list shows groups of standard recognition event codes. Production sites might encounter additional codes and tokens not described here.
| SWIapps—application session | Written when the application provides a session and step identifier. |
| SWIfrmt—format | Written at the beginning of the interaction and identifies the format of the events written by Recognizer. |
| SWIendp—end pointer | Written for every recognition attempt (where start of speech is detected), whether the recognition was successful or not. |
| SWIrcst—recognition start | Logged at the start of recognition. |
| SWIrrst—recognizer restart | Logs the restart of recognition on the next candidate chunk of audio when the recognizer is set to magic_word or selective_bargein_mode. |
| SWIrrcn—rejected chunk | Logs the recognition failure of a single candidate chunk of audio when the recognizer is set to magic_word or selective_bargein_mode. |
| SWIrcnd—recognition end | Logged at the end of recognition. Note: The entries in the log are not guaranteed to be sorted by the nbest result at the time when SWIrcnd is printed. |
| SWIstop—recognizer stop event | Writes to the call log the reason the recognizer stopped. |
| SWIrslt—recognizer result | Logs the complete XML recognition result at the end of a successful recognition when a voice platform requests a result. |
| SWIdtmf—DTMF result | Shows the DTMF string and its value as determined by the grammar. |
| SWIacsv—acoustic accumulator save event | Written for each saved statistics file. |
| SWIacum—acoustic accumulation event | Written whenever the Recognizer collects a statistic as part of its self-learning feature (acoustic adaptation). |
| SWIaupd—acoustic model update event | Written whenever the Recognizer updates its acoustic model. |
| SWIcach—caching event | Provides a periodic summary of grammar caching activities. |
| SWIgrld—grammar load | Summarizes the loading of a grammar. |
| SWIiffi—fetched grammar file | Logs the filename of a copied grammar file saved for debugging purposes. |
| SWIliss—recognizer license start | Triggered at the start of a session and describes recognizer license usage at the beginning of a call to the system. |
| SWIepst—endpointer start | Signals that the endpointer has started working on trying to detect the start of speech. |
| SWIepms—endpointer milliseconds | Signals that the external endpointer is done with trying to detect the beginning of speech. |
| SWIepss—endpointer license start | Triggered at the start of a session and indicates the endpointer license usage at the beginning of a call to the system. |
| SWIepse—endpointer license end | Triggered at the end of a session and indicates endpointer license usage at the end of a call to the system including the duration (in seconds) a license was held for the call. |
| SWIlise—recognizer license end | Triggered at the end of a session and describes recognizer license usage at the end of a call to the system including the duration (in seconds) a license was held for the call. |
| SWIlock—license lock | Logs the time when a license is checked out (locked) during recognizer initialization and shows which license features are used. |
| SWIunlo—license unlock | Logs the time a license is released (unlocked). |
These events are logged by Nuance Dialog Modules, and by applications that need the rich reporting. Every phone call to the system is a session that includes many of these events. See Application-defined logging events.
| SWIdmst—Dialog Module start | Indicates the start of a module. |
| SWIdmnd—Dialog Module end | Indicates the end of a module. |
| SWIprst—Prompt Start | Indicates that a prompt was played. |
| SWIphst—Phase Start | Logged by multi-phase modules when entering a phase (not logged by single-phase modules). |
| SWIphnd—Phase End | Logged by multi-phase modules when ending a phase (not logged by single-phase modules). |
| SWIstst—step start event | Indicates the start of a step. |
| SWIstnd—step end | Describes the result of a step’s recognition. |
| SWItyst—try start | Indicates the start of a try. |
| SWItynd—try end | Indicates the end of a try. |
These events are based on Nuance Dialog Modules—which logs them automatically—and use the following terminology:
- Modules are voice application routines that collect one or more pieces of related information, such as an account number or address. Nuance Dialog Modules are building-blocks that automate many of these routines.
- Phases occur when a module collects multiple different, but related pieces of information. For example, an address module collects a street number and name, a city, and a postal code. These are each a different phase of the module. However, collecting different information of the same type typically happens in one phase, such as when collecting a first and last name.
- A Try is a set of one or more recognition steps attempting to get a piece of information, and consisting of a single collection step and zero or more confirmation steps. When a collection has a high confidence, the try usually ends without a confirmation. The try also completes when the collection is confirmed. Rejecting a confirmation ends a try and typically starts another one with the same module.
- A Step is single recognition request and result, which can include collecting an utterance or DTMF, or resulting in a time-out or hang-up.
- A Slot is a specific type of information collected from the module, such as a departure city. A multiple-slot module can collect more than one piece of information, such as the make, model, and year a car was made.
The following list shows groups of standard Vocalizer event codes.
| NVOCapps—application session | Written when the application provides a session and step identifier using SSML <meta>. |
| NVOCaudf—first audio | Indicates the first audio packet for a synthesis operation. |
| NVOCaudn—next audio | Indicates an audio packet for a synthesis operation after the first audio packet. |
| NVOCinpt—input text | Provides the input text for the speak request. |
| NVOClise—license end | Triggered at the end of a synthesis operation and describes the count of licenses in use prior to freeing the license. |
| NVOClisr—license refused | Indicates a synthesis operation failed because there was no license available. |
| NVOCliss—license start | Triggered at the start of a synthesis operation and describes the count of licenses in use after incrementing for the new license. |
| NVOClock—license lock | Logs the time when a license is checked out (locked) during Vocalizer initialization and shows which license features are used. |
| NVOCunlo—license unlock |
Logs the time a license is released (unlocked). |
| NVOCifst—internet fetch start | Indicates an Internet fetch has started. |
| NVOCifnd—internet fetch end | Indicates an Internet fetch has ended. |
| NVOCfrmt—file format | Indicates the file format for Vocalizer-written event log files. |
| NVOCsynd—synthesis end | Logged at the end of synthesis. |
| NVOCsyst—synthesis start | Logged at the beginning of synthesis. |
| NVOCsysw—synthesis switch | Logged when a mid-synthesis voice switch occurs and reports the new voice. |
Applications can define and log additional events, and Nuance speech products can show them in the call log for an individual call. When generating an event entry:
- Each token in the log is a name/value pair separated by an equal sign character (=). For example:
APPSERV=127.0.0.1
- Each log entry must have an EVNT token that identifies the event. The event name can be any alphanumeric string except one of the Reserved events.
EVNT=SWIsvst
- Additional tokens separated by vertical bar characters (|), like this:
EVNT=SWIsvst|SVNM=MyApplicationName|APPSERV=127.0.0.1
These event names and prefixes are reserved and cannot be used for application-defined events.
| ALT* | BROWSER_ID | NVOC* |
| ANI | CALL_LOCAL_URL | SWI* |
| DNIS | CALL_REMOTE_URL | TASK_BEGIN |
| APP_INFO | ENTERING_FORM | TRANSFER_DURATION |
| APP_JAVASCRIPT_LOG | ENTERING_FORM_ITEM | TRANSFER_STATUS |
| APP_VOICEXML_LOG | EXECUTING_URL | TRANSITION |
| BROWSER | NUAN* | — |
Required application events
To merge the log with recognizer logs, the application must:
- Log the OSCL event and OSLE token sometime between the call start (SWIclst) and call end (SWIclnd) events.
- Generate at least these events, in this hierarchy:
SWIclst—call start (one required)
[dialog module block] (one or more)
SWIclnd—call end
Where a dialog module block consists of:
SWIdmst—Dialog Module start (one or more)
…
SWIstst—step start event (one for each step)
SWIprst—Prompt Start (one required)
[recognition] (one per step)
…
SWIstnd—step end
…
SWIdmnd—Dialog Module end
Where a recognition is a collection or a confirmation attempt that passes the session and step IDs to the recognizer when loading a grammar.
Recommended events
To generate the richest possible reports, applications log the following events in this hierarchical order:
SWIclst—call start (one required)
[dialog module block] (one or more)
SWIclnd—call end
Where a dialog module block consists of:
SWIdmst—Dialog Module start (one or more)
SWIphst—Phase Start (none, one, or more)
[try block] (one or more)
SWIphnd—Phase End
SWIdmnd—Dialog Module end
Where a try block (a collection attempt) consists of:
SWItyst—try start (one required)
SWIprst—Prompt Start (none, one, or more)
[recognition block] (one or more)
SWIprst—Prompt Start (none, one, or more)
SWItynd—try end
Where a recognition block (a collection or a confirmation) consists of
SWIstst—step start event (one required)
SWIprst—Prompt Start (none, one, or more)
SWIrcst—recognition start
SWIepst—endpointer start
SWIendp—end pointer (none, one, or more)
SWIrcnd—recognition end
SWIrslt—recognizer result (For Nuance Recognizer logs)
SWIendp—end pointer (none, one, or more)
SWIstop—recognizer stop event (none or one)
SWIdtmf—DTMF result (none or one)
SWIstnd—step end
Note: Many of the application logging concepts (such as phase and try) and events are based on the technology of Nuance Dialog Modules. See Dialog Module logging events for terminology definitions.
Commonly logged events
Here are some of the non-required events that an application typically logs. They often have application-specific values.
| DNIS—Dialed number identification | Phone number that the caller dialed. |
| Enc—Encrypted content | Encrypted content. |
| ERROR—Generic error | Application-defined generic error. |
| NVOCinpt—input text | Input text for the speak request. |
| OSCL—client log entry | Internet fetch has started. |
| SWIdbrx—database query completion | End of a database query. |
| SWIdbtx—database query begin | Start of a database query. |
| SWIlang—Call language | Spoken language of the call. |
| SWIppnd—Play Prompt end | End of a Play Prompt node. |
| SWIppst—Play Prompt start | Start of a Play Prompt node. |
| SWIdmst—Dialog Module start | Start of a module. |
| SWIdsst—Decision state start | Start of a Decision node. |
| SWIsum—summary statistics | Provides up to four application-defined values to be used in the Application Summary report’s "Customer Specified Sum" metrics. |
| SWIsurvey—gathers information from callers | Survey questions and responses. |
| SWIsvst—service start | Identifies the application name (service name). |
| SWItrfr—transfer event |
Indicates call was transferred. |
| SWIunid—unique call ID | Logs a unique ID for the call. |
Note: The content in this topic is for Dragon Voice in on-premise deployments.
The following list describes the standard events codes for the Krypton recognition engine.
| KRrcst—Krypton recognition start | Indicates the beginning of a Krypton engine recognition. |
| KRstop—Krypton recognition stopped | Written when a Krypton engine recognition is terminated. |
| KRrcnd—Krypton recognition end | Indicates the end of a Krypton engine recognition. Confirms completion of the Recognize command and of release of any associated resources. |
| KRrslt—Krypton recognition result | Logs the final recognition result received from the Krypton engine. |
| KRvdld—VocDelta load | Written when domain language models or wordset files are loaded. |
The Speech Server is responsible for logging events related to:
- Start of speech endpointing (for example, SWIendp event), including the waveform captured (NUANwvfm event).
- A stop event due to hang-up or DTMF detection, in which case the Speech Server will log why the stop event occurred (SWIstop).
- Events related to DTMF processing (such as SWIdtmf).
Note: The content in this topic is for Dragon Voice in on-premise deployments.
The following list describes the standard Natural Language Engine events (and Nuance Text Processing Engine events, where appropriate).
| Load events | |
| NLEplld—Pipeline load | Logged when a semantic model is loaded. A semantic model is required to perform interpretation. |
| NLEwsld—Wordset load | Logged when a dynamic wordset is loaded. Wordsets are containers of words that customize the vocabulary. |
| Interpretation events | |
| NLEplst—Pipeline start | Indicates the start of an interpretation. |
| NLEinst—QuickNLP interpretation start | Event written just before calling the core engine to perform the interpretation request. Includes the input. |
| NLEtokst—Tokenization start | Event written at the beginning of tokenization of input to the interpretation command. Includes the tokenizer input. |
| NLEtoknd—Tokenization end | Event written at the end of tokenization of input to the interpretation command. Contains the tokenizer output. |
| NLEinnd—QuickNLP interpretation end | Event written just after the interpretation call to the core engine has completed. Includes the output. |
| NLEplnd—Pipeline end | Written just before returning the response to the interpretation command. |
| NLErslt—Final result | Final interpretation result. |
This diagram illustrates how results are logged as a recognition result moves from the Krypton to the NLE/NTpE pipeline for interpretation. The NLP service is the component responsible for sending the recognition/interpretation results to the Speech Server as well as the call log events.
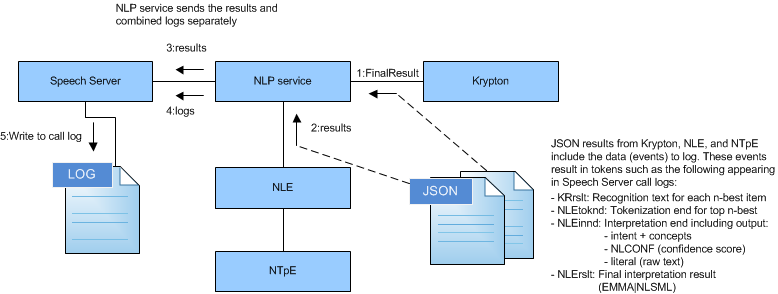
Along with the event codes, the Speech Server call log will contain the recognition result, the audio captured, speech endpointing results, any stop events due to hang-up, and any DTMF processing results.
Related topics
Reference
