Provide speech response using recorded speech audio
TTS synthesized speech is one way to provide speech responses in voice or omni-channel applications. Another option is to use recorded audio files.
This second option is available when an Audio Script message has been defined in Mix.dialog for the interaction. When using this option, you need to pre-record and store speech audio files within the client application. In this case, the StreamOutput response from DLGaaS includes, within the payload of its response field, local URI references for the appropriate audio file(s) to retrieve and play .
The message contents of both the messages and qa_action fields in the payload can contain an audio field with one or more Message.Audio messages. The contents give details for recorded audio versions of the message contents. Message.Audio contains two key fields:
uri: string that indicates the name and local path in the application to find the appropriate recorded audio filetext: provides text for TTS backup if there is no audio file or the audio file cannot be played or found
Audio files and naming
Dialog expects recorded audio files related to a message to have file names derived systematically from the Audio File ID, or, if that is not specified, from the Message ID in Mix.dialog. How the file names are specified depends on whether the message is static or dynamic.
Static message audio file naming
Static messages have fixed contents and are the same every time they are used. An example of this is a standard greeting message or question posed routinely to the user.
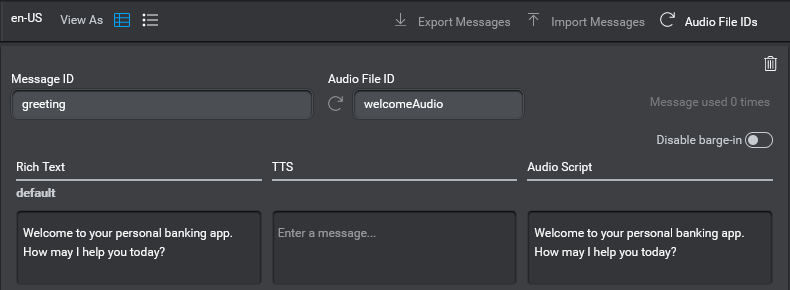
For example, suppose in a banking application, the application sends an initial greeting message with a question to open the interaction, as follows:
“Welcome to your personal banking app. How may I help you today?”
In the case of a static message, the client application receives a payload message with one Message.Audio entry providing reference to a single audio file. Only one file is needed because the contents are fixed and can be recorded in one piece. If an Audio File ID is available, the file name is of the form Audio_File_ID. If only a Message ID is available, the file will instead be named Message_ID.
For the example above, the following payload message audio field contents would be returned:
#StreamOutput
{
"response": {
"payload": {
"messages": [],
"qa_action": {
"message": {
"visual": [{ "text": "Welcome to your personal banking app. How may I help you today?"}],
"audio": [{"text": "Welcome to your personal banking app. How may I help you today?", "uri": "en-US/prompts/default/IVRVoiceVA/welcomeAudio.wav?version=1.0_1612217879954"}]
}
}
}
}
}
Dynamic message audio file naming
Dynamic messages have all or part of the message depending on the value of session variables. As such, the full contents of the message are only knowable at runtime.
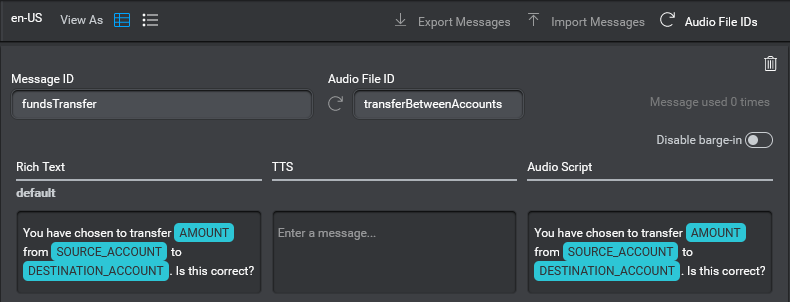
For example, suppose that in a banking application you want to read back the details of the requested transaction to the user and get their confirmation. So in the case of a funds transfer scenario, the message might be defined in Mix.dialog as follows:
“You have chosen to transfer AMOUNT from SOURCE_ACCOUNT to DESTINATION_ACCOUNT. Is this correct?”
Here, AMOUNT, SOURCE_ACCOUNT, and DESTINATION_ACCOUNT are placeholders for values of variables only known at runtime based on what the user says. The rest of the message is static content that is always the same.
In the case of a dynamic message with placeholders for variable values, the message is broken into parts representing the different static and dynamic segments in the message. The client application receives a payload message with multiple Message.Audio entries providing reference to either static audio files or fallback text for TTS.
Suppose that at runtime, you have:
- AMOUNT="$500"
- SOURCE_ACCOUNT=“chequing”
- DESTINATION_ACCOUNT=“savings”
The message breaks down into seven segments, alternating between static and dynamic content:
- You have chosen to transfer (static)
- $500 (dynamic)
- from (static)
- chequing (dynamic)
- to (static)
- savings (dynamic)
- Is this correct? (static)
Seven audio entries are sent within the response payload representing the static and dynamic segments.
If the message has an Audio File ID transferBetweenAccounts, and .wav was set as the desired audio file format in Mix.dialog, then Mix.dialog would expect four recorded audio files corresponding to the four static segments with file names:
- transferBetweenAccounts_01.wav for “you have chosen to transfer”
- transferBetweenAccounts_03.wav for “from”
- transferBetweenAccounts_05.wav for “to”
- transferBetweenAccounts_07.wav for “Is this correct?”
Here the numbers added to the end of the file name correspond to the segment number within the message.
For the dynamic segments, text is provided so that the client application can make a runtime request for TTS audio.
Here’s the payload message audio field contents for the same example:
# StreamOutput
{
"response": {
"payload": {
"messages": [],
"qa_action": {
"message": {
"visual": [{ "text": "You have chosen to transfer $500 from checking to savings. Is this correct?"}],
"audio": [{"text": "You have chosen to transfer", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_01.wav?version=1.0_1612217879954"},
{"text": "$500"},
{"text":"from", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_03.wav?version=1.0_1612217879954"},
{"text": "chequing" },
{"text": "to", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_05.wav?version=1.0_1612217879954" },
{"text": "savings" },
{"text": "Is this correct?", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_07.wav?version=1.0_1612217879954" }
]
}
}
}
}
}
For the static segments with URIs, the client application can retrieve the audio files at the expected location in the application files.
For the dynamic segments with only text, the client application needs to obtain synthesized speech by sending the text segments to TTS.
Once the recorded audio files and the TTS audio are ready, the client application can play the different bits of audio for the message together.
Note:
For best results, the voices for the recorded audio narrator and the TTS synthesized voice should sound as similar as possible.DynamicMessageReference
DynamicMessageReference is a predefined variable schema in Mix.dialog used for audio messages.
This schema includes two fields:
audioFileName: URI with local path and file name, with file extension includedttsBackup: Alternative text for TTS when the audio file is unavailable.
To use this, do the following in Mix.dialog:
-
Create a variable based on this schema.
-
Create a data access node to obtain the field values for the variable at runtime from the client application or a backend data source.
-
Put the variable as a dynamic placeholder under Audio Script modality in the message definition in Mix.dialog.
At runtime, Mix.dialog gets the audioFileName and ttsBackup from the data source, and sends this to the client application as part of a response payload Message.Audio. There, it can be handled similarly to the case of a static message audio file.
TTS backup
In any case where either no URI is provided for a segment of the message or the audio file is not available at runtime, the backup text can be used to generate audio via TTS. The client application needs to make a separate request to TTS to generate speech for each section of text.
Dynamic concatenated audio
When Mix dialogs are driven by VoiceXML applications, Audio Script messages for certain supported languages are played using audio files from dynamic concatenated audio packages. These packages contain regularly used component snippets of recorded audio with different options for intonation. In this case, speech audio for both static and dynamic content is put together and played from recorded audio files, concatenated together with intonation and formatting driven by message formatting applied in Mix.dialog.
One benefit to this approach is that the same voice is used for both static and dynamic content, and can sound better than the combination of recorded plus TTS. Note that this option is only available for certain languages.
For more information see Dynamic concatenated audio playback options.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.