Train and test your model
With your model elements defined and your training set built and verified, you can now train and test your model.
Train your model
Training is the process of building a model based on the data that you have provided.
If your project (or locale) contains no samples, you cannot train a model. You need at least one sample sentence that is either intent-assigned or annotation-assigned. Be sure to verify samples.
Developing a model is an iterative process that includes multiple training passes. For example, you can retrain your model when you add or remove sample sentences, annotate samples, verify samples, include or exclude certain samples, and so on. When you change the training data, your model no longer reflects the most up-to-date data. As this happens, the model must be retrained to enable testing the changes, exposing errors and inconsistencies, and so on.
Training a model
To train your model:
- In Mix.nlu, click the Develop tab.
- (As required) Select the locale from the menu near the name of the project.
- Click Train Model.
Mix.nlu trains your model. This may take some time if you have a large training set. A status message is displayed when your model is trained.
To view all status messages (notifications), open the Console panel ![]() .
.
Training a model that includes prebuilt domains
If you have imported one or more prebuilt domains, click the Train Model button to choose to include your own data and/or the prebuilt domains. Since some prebuilt domains are quite large and complex, you may not want to include them when training your model.
To train your model to include one or more domains:
-
Click the arrow beside Train Model. The list of prebuilt domains is displayed in addition to your own data. In the example below, notice that the Nuance TV and Nuance Weather prebuilt domains have been imported into the project:
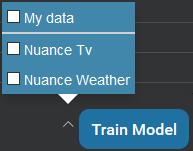
-
Check the domains you want to include.
-
Check My data to include your data.
-
Click Train Model.
Training error log
Sometimes during the training process, issues can arise with the training set. This can result in either warnings or errors or both.
Errors are more serious issues that cause the training to fail outright.
Warnings are other issues that are not serious enough to make the training fail but nevertheless need to be brought to your attention.
Samples with invalid characters and entity literals and values with invalid characters are skipped in training but the training will continue. Such a sample is set to excluded in the training set so that it will not be used in the next training run or build.
Detailed information about any errors and warnings encountered during training is provided as a downloadable log file in CSV format. If only warnings are encountered, a warning log file is generated. If any errors are encountered, an error log file is generated describing errors and also any warnings.

A download link appears next to the Train Model button. The type of log file (error vs warning) is indicated by an icon beside the link, ![]() for errors and
for errors and ![]() for warning. Click to download the CSV file.
for warning. Click to download the CSV file.
The file includes one line for each error and/or warning encountered, with two columns. One column gives the severity of the issue, either WARNING or ERROR, while the other column gives a message containing details.

Test your model
After you train your model, you can test it interactively in the Try panel. Use testing to tune your model so that your client application can better understand its users.
The Try panel is available in both the Develop and Optimize tabs.

Try to interpret a new sentence
To test your model:
- In Mix.nlu, click the Develop tab.
- (As required) Select the language from the menu near the name of the project.
- Click Try. The Try panel appears.
- Enter a sentence your users might say and press Enter.
Read and understand the results
The Try panel presents the response from the NLU engine.
The Results area shows the interpretation of the sentence by the model with the highest confidence. In the image here, the Results area displays the orderCoffee intent with a confidence score of 1.00. The Results area also shows any entity annotations the model has been able to identify.
Note that the Results area will not reflect any the changes you have made to intents and entities since the last time you trained the model.
No annotations appear in the Results area if the NLU engine cannot interpret the entities in your sample using your model. Also, there is no annotation for dynamic list entities. Only your client application can provide this information at runtime.
Full information from the NLU engine, including all interpretations, appears formatted as a JSON object. For easier reading, you can expand or collapse sections of the information. You can also copy the results JSON, or sections of it to the clipboard.
Add the sentence to the training set
If you are unsatisfied with the result in Try, you can add the sentence to your project as a new sample and then manually correct the intent or annotations. Realistic sentences that the model understands poorly are excellent candidates to add to the training set. Adding correctly annotated versions of such sentences helps the model learn, improving your model in the next round of training.
To add a sentence you have just tested, click Add Sample. The sample will be added to the training set for the intent identified by the model, along with any entity annotations the model recognized.
If Try recognized an intent, but no entities, the new sample will be added as Intent-assigned.
If Try also recognized entities, the new sample will be added as Annotation-assigned.
If the same sentence is already in the training set with the same annotations, the count will be updated for that sentence. If the same sentence is already in the training set, but with different annotations, then to maintain consistency in the training set you will not be able to add the sample from Try.
Correct errors in the interpretation
Once the sample is added into the training set, make corrections to the intent and annotation labels to help the model better recognize such sentences in the future.
If the recognized intent was incorrect, change the intent.
If the annotated entities were incorrect, edit the annotation.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.