Handling sensitive information
Sometimes when building an NLU model for your application, you will need to handle user inputs that contain sensitive personally identifiable information (PII). Sensitive PII is personal data, not generally easily accessible from public sources, that alone or in conjunction with other data can identify an individual.
Examples of PII
Sensitive PII includes data such as:
- Full name
- Social Security Number or Social Insurance Number
- Driver’s license
- Full mailing address
- Credit card details
- Passport details
- Financial information
Masking PII user data in logs with sensitive flag
When collecting such information during an interaction with a user, it is important to redact this data in logs to protect the users.
In order to be able to successfully redact sensitive collected data in logs, you need to do three things in Mix.nlu:
- Define an entity to capture that piece of data.
- Mark the entity as sensitive.
- Create some training set samples including that entity and annotate the entity contents to help your model learn to identify it, but do not use real PII in your training set samples.
Mix.nlu allows you to mark any entity as Sensitive in the Entities panel. Once an entity has been marked as sensitive, user input interpreted by the model as relating to the entity at runtime will be redacted in call logs.
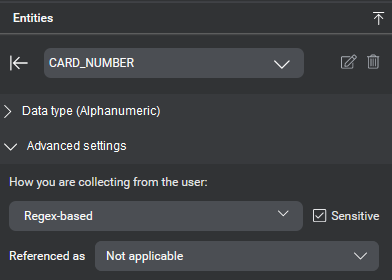
Similarly, entities and contents of variables can be marked as sensitive in Mix.dialog and are then handled the same at runtime.
Warning:
Note that an entity defined in relationship to custom entities via isA or hasA does not automatically inherit the sensitive flag from the original entities. You need to separately mark the new entity as sensitive.Sensitive data and training set samples
If you are using entities that collect sensitive data in your application, do not use real PII in your training set samples. It is your responsibility to keep real PII out of your training set. Consider the following alternatives for training on these entities:
- Define the entity contents using a regex or GrXML grammar
- Generate representative synthetic training examples
Refining recognition of sensitive entities via the training set
Effective redaction of sensitive data depends on the sensitive entity being recognized by the NLU model. Remember that no NLU model will have perfect performance. It is possible that your model will fail to recognize an entity in a specific user utterance, particularly when the utterance does not closely resemble a sample in the training set. In this case, the data will not be redacted, and the sensitive data will appear in the call logs. You are responsible to monitor your call logs, identify gaps, and add training samples as needed to improve performance in an iterative fashion.
Related topics
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.