Fundamentals
Before you can design a multichannel conversational interaction (dialog), you need to understand what your customers mean, not just what they say, tap, or type.
Whether you engage with customers via a web application, mobile app, interactive voice response (IVR) system, smart speakers, and/or chatbots, the conversation starts with natural language understanding (NLU).
More Info:
- Want to get started with the APIs?
If you are an application developer and want to immediately start working with Mix.api or the gRPC runtime APIs, rather than learn more about natural language understanding and the DIY tools available to Nuance Mix, see the APIs section. - Want to get started using Mix tooling?
To get started using Mix.nlu, see Mix.nlu. To walk through designing a simple chat dialog, see Mix.dialog.
NLU
Natural language understanding enables customers to make inquiries without being constrained by a fixed set of responses. This conversational experience allows individuals to self-serve and successfully resolve issues while interacting with your system naturally, in their own words.
In other words, natural language understanding is the ability to process what a user says (or taps or types) to figure out how it maps to actions the user intends. The application uses the result from NLU to take the appropriate action.

Sample use case: Coffee app
For example, suppose you have developed an application for ordering coffee. You want users of the application to be able to make requests, such as:
- “I’d like an iced vanilla latte.”
- “Cup o’ joe.”
- “How much is a large cappuccino?”
- “What’s in the espresso macchiato?”
Your users have countless ways of expressing their requests. To respond effectively, your application first needs to recognize the users’ actual words. When users type their own words or tap a selection, this step is easy. But when they speak, their voice audio needs to be turned into text by a process called Automatic Speech Recognition, or ASR.
Once your application has collected the words spoken by the user, it then needs to map these words to their underlying meaning, or intention, in a form the application can understand. This process is called Natural Language Understanding, or NLU.
Mix.nlu provides the complete flexibility to build your own natural language processing domain, and the power to continuously refine and evolve your NLU based on real word usage data.
Developing an NLU model
Within the Mix.nlu tool, your main activity is preparing data consisting of sample sentences that are representative of what your users say or do, and that are annotated to show how the sentences map to intended actions.
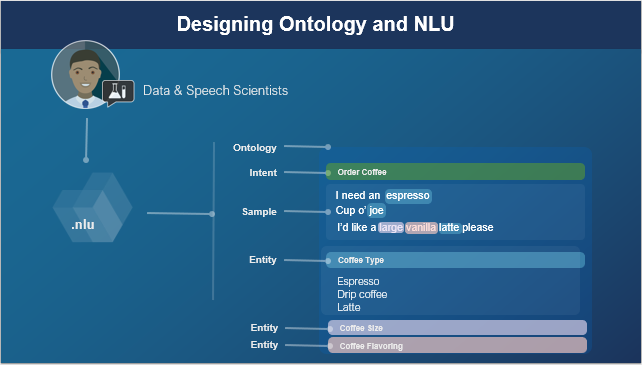
When annotating a sample sentence, you indicate:
- The function to be performed. For example, to order a drink, or to find out what is in one. What does the user want to do?
- The parameters for that function. For example, at minimum the type of drink and the size. You might also, depending on the needs of your business (and, therefore, the application), collect the type of milk or flavoring offered, and the temperature (iced or hot). What does the dialog application need to know to complete the action?
In “NLU-speak,” functions are referred to as intents, and parameters are referred to as entities.
The example below shows a sample sentence, and then the same sentence annotated to show its entities:
- I’d like an iced vanilla latte
- I’d like an [Temperature]iced[/] [Flavor]vanilla[/] [CoffeeType]latte[/]
In the example, the intent of the whole sentence is orderCoffee and the entities within the sentence are [Temperature], [Flavor], and [CoffeeType]. By convention, the names of entities are enclosed in brackets and each entity in the sentence is delimited by a slash [/].
Together, intents and entities define the application (or project’s) ontology.
The power of NLU models
In practice, it is impossible to list all of the ways that people order coffee. But given enough annotated representative sample sentences, your model can understand new sentences that it has never encountered before.
In Mix.nlu, this process is called training the NLU model. Once trained, the model is able to interpret the intended meaning of input such as utterances and selections, and provide that information back to the application as structured data in the form of a JSON object. Your application can then parse the data and take the appropriate action.
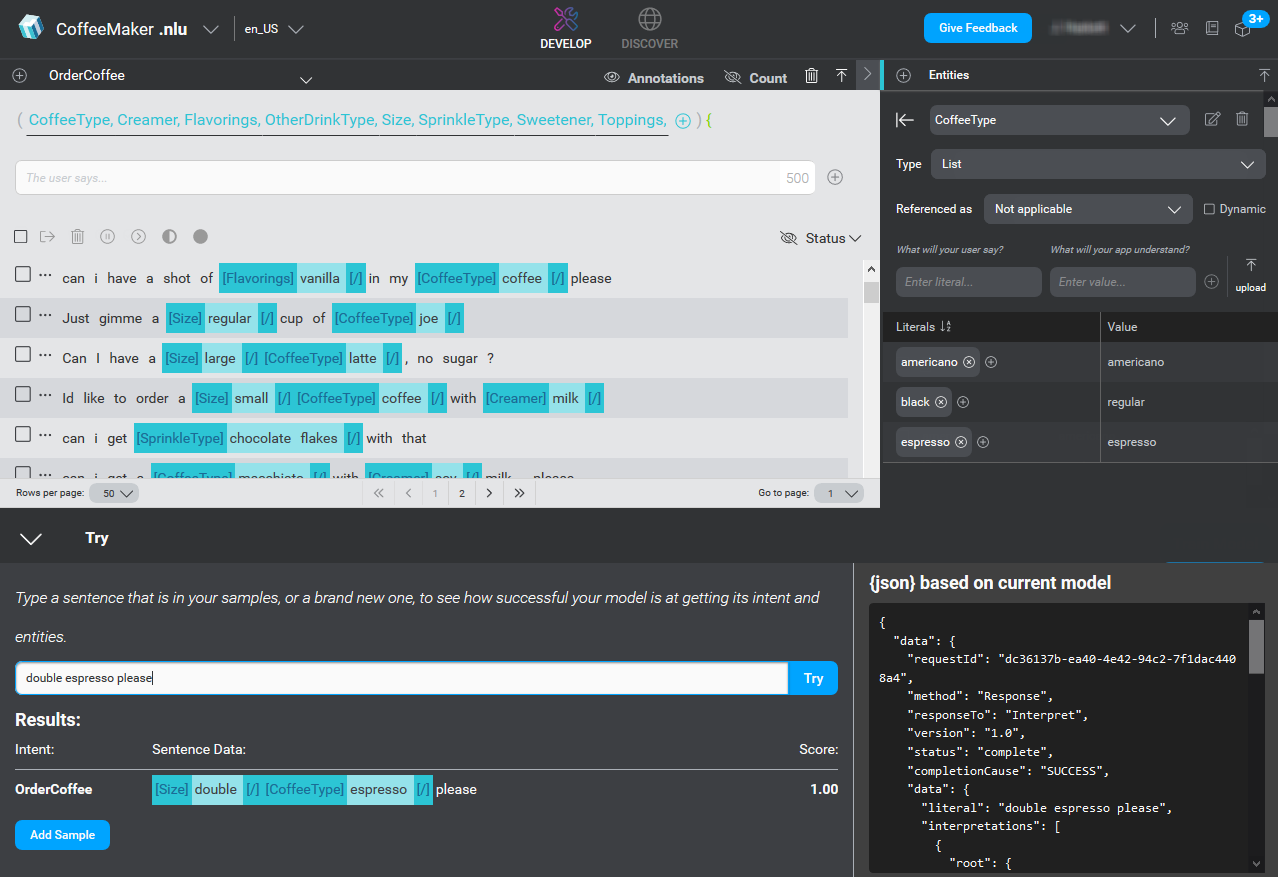
Iterate! Iterate! Iterate
Training a model is an iterative process: you start with a small number of samples, train and test a model, add more samples, train and test another version of the model, and continue adding data and retraining the model through many iterations.
Here is a summary of the general process:
- What can the application do? Think about what you want your application to do.
- What types of things will users say? Add sample sentences that users might say to instruct the application to do those things.
- What does the user mean? Annotate the sample sentences with intents and entities.
- Train a simple model Use your annotated sentences to train an initial NLU model.
- How well does it work? Test the simple system with new sentences; continue adding annotated sentences to the training data.
- Test it with real users Build a version for users to try out; collect usage data; use the data to continue refining the model.
Dialog
From an end-user’s perspective, a dialog-enabled app or device is one that understands natural language, can respond in kind, and, where appropriate, can extend the conversation by following up the user’s input with appropriate questions and suggestions.
In other words, it’s a system designed for your customers that integrates relevant, task-specific, and user-specific knowledge and intelligence to enhance the conversational experience.
Sample use case: Coffee shop
For example, suppose you’ve developed an application for ordering coffee. You want your users to be able to make conversational requests such as:
- "I need an espresso"
- "Large dark roast coffee"
- "Can I have a large coffee, please? Wait, make that decaf."
- "How much is a cappuccino?"
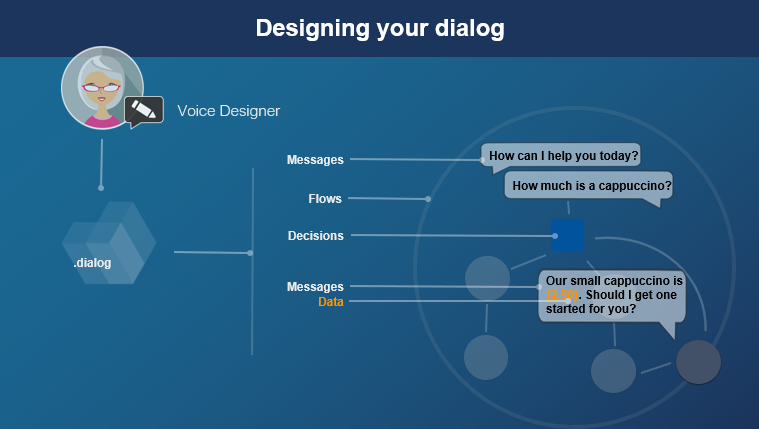
Your dialog model depends on understanding the user’s input, and that understanding is passed to the dialog in the form of ASR and NLU models. Mix.nlu is where you define the formal representation of the known entities for the purpose of the dialog and the relationships among them (the ontology), to continue the conversation. For example, by saying:
- "Sure, what size espresso would you like?"
- "OK, confirming a large coffee with no milk or sugar. Is that right?"
- "One large decaf coming up."
- "Our small cappuccino is $2.50. Should I get one started for you?"
Once you have a set of known entities from NLU, you’re ready to start specifying your dialog. Your dialog will be defined as a set of conditional responses based on what the system has understood from NLU, plus what it knows from other sources that you integrate (for example, from the client device’s temperature sensor or from a backend data source).
For example, if the user’s known intent is orderCoffee, but the “size” concept is unknown, you might specify that the system:
- Explicitly ask the user to provide the size value: "Sure, what size?"
- Set a default value such as “regular” and ask the user to implicitly confirm the selection: "Sure, one regular coffee coming up!"
- Ask the client app to query a database to return the user’s preferred coffee size: "Sure, your usual venti?"
Mix.dialog offers several response types that can be specified at each turn, including questions for clarifying input, gathering information, confirming information, or guiding the user through a task.
Developing a dialog model
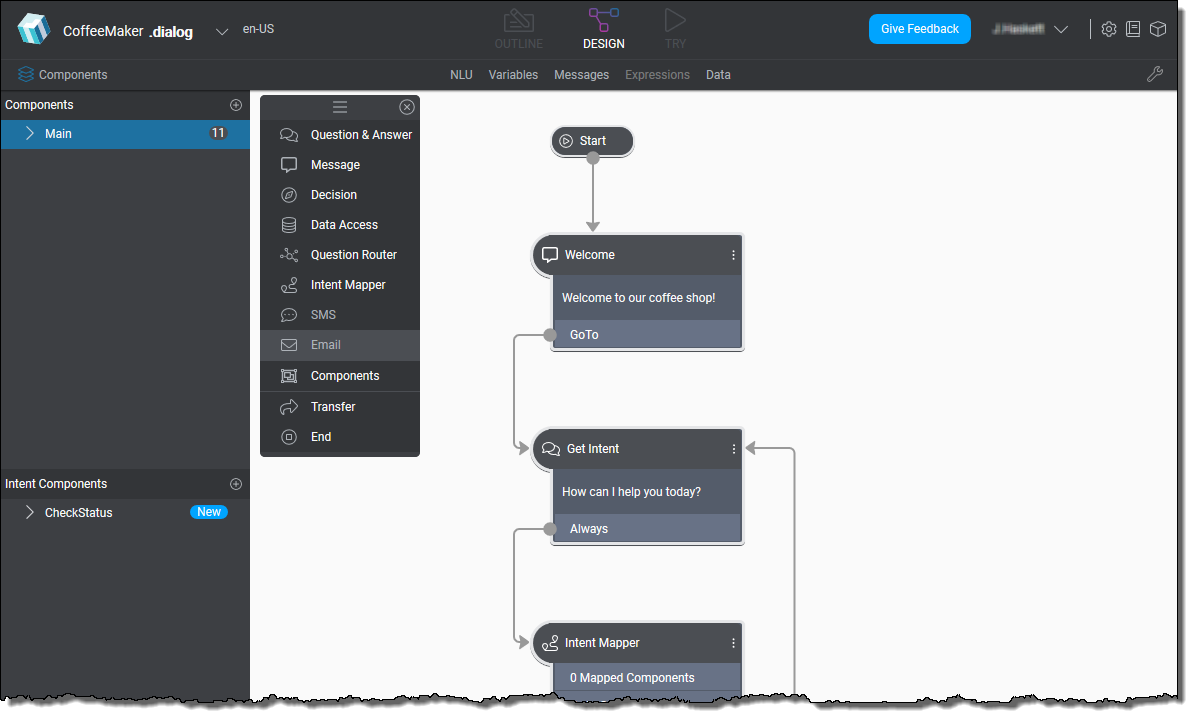
The Mix.dialog tool enables you to design and develop advanced multichannel conversational experiences.
In particular, it allows you to:
-
Define a set of conditions that describe how your system should respond to what it understands (the “understanding” part is specified by you in Mix.nlu).
-
Drag and drop nodes to quickly create your conversational flow and fill in the details, sharing or branching behavior based on channel, mode, or language for optimal user experience.
-
Take in information that you have about your users, whether from a device or from a backend system, and use that information in real time to provide personalized information and guidance.
-
Instantly try out your conversations as you work at any time during the process in a preview mode. The Mix.dialog Try tab simulates the user experience on different engagement channels and lets you observe the dialog flow as it happens.
Like training an NLU model, building a natural language application is an iterative process. The ability to try out the dialogs you’re defining before deploying them is a key part of dialog modeling.
Mix runtime engines
Apart from the two graphical tools, Mix.nlu and Mix.dialog, Mix offers several runtime engines for executing your applications in testing and in production. These engines are all hosted on the Mix platform, meaning you don’t need to install them but can simply call them using their gRPC APIs.
Mix hosts two recognition engines, two voice synthesis engines, an NLU engine, and a dialog conversation engine. Between them, these engines power the speech and natural language applications you develop using Mix.
For details, consult About the runtime engines.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.