Import Discover data
Add samples to the training set
From the Discover tab, you can add selected samples for valid intents directly to the training set.
There are two options available for this:
- Add an individual sample
- Add multiple samples with bulk-add
Samples can be added to the training set under one of three verification states:
- Intent-assigned
- Annotations-assigned
- Excluded
Note the following behaviors which apply to importing individual samples and bulk imports:
- If the intent is valid, and there are no flagged entities in the sample, the sample will be added to the inferred intent, along with any annotations, and set to the chosen verification state.
- If the intent is valid, but any of the entities in the sample are flagged, all entity annotations will be removed from the sample on import.
- If the intent is invalid, the sample cannot be selected for import as is. First you must first change the intent for the sample to a valid intent.
- If any of the content in a sample is redacted (due to sensitive information), you will not be able to select the sample to import.
- For samples with intent set to UNASSIGNED_SAMPLES, any entity annotations—even if they are all valid—will be removed from the sample on import.
Note that once a sample has been imported to the training set, the sample will remain in Discover.
Add an individual sample
To add a sample with a valid intent to the training set:
-
Click the add sample
 icon to open the add menu.
icon to open the add menu. -
Select one of the verification state options from the menu to add the sample to the training set with the chosen verification state.

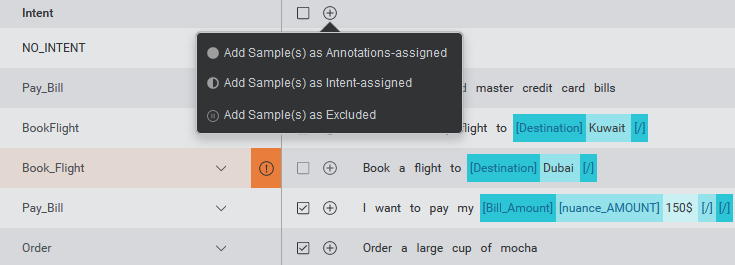
Add multiple samples using bulk-add
To save time adding multiple samples from Discover to your training set, you can select multiple samples at once for import, and then add the samples to the training set in a chosen verification state.
Checkboxes are provided beside each sample to select the samples. A checkbox in the header above the samples allows you to select all selectable samples on the current page.
A bulk-add samples button in the header allows you to choose the target verification state for the selected samples.
To add a selection of samples:
-
Use the checkboxes to select samples.
-
Select the desired state for the samples in the bulk actions bar above the samples.
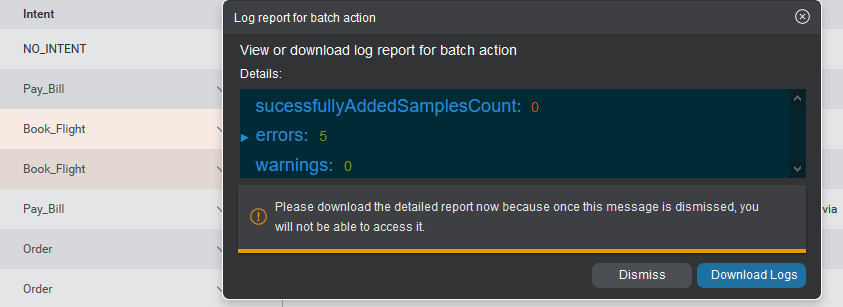
Download bulk-add errors data
When bulk-adding multiple samples, it is possible that errors and warnings will be produced. A pop up appears when a bulk-add is completed, summarizing the results of the operation, including any errors and warnings. To read detailed error logs, you can download an errors log file in CSV format. A Download Logs button for the CSV file will be displayed in the popup. To download the file, click the button.
Download Discover data
You can download the currently selected data from the Discover tab as a CSV file. This includes, for each sample, any entity annotations identified by the model and displayed in Discover.
If filters are currently applied, only the filtered data will be downloaded.
To download the sample data as CSV, click on the download icon ![]() above the table. You can then process this data externally into a file format that can be imported into Mix.nlu. For more information about importing data into a model, see Importing and exporting data.
above the table. You can then process this data externally into a file format that can be imported into Mix.nlu. For more information about importing data into a model, see Importing and exporting data.
If you change the application, associated context tag, environment, or date range using the source selectors, the download option is diabled until you press Reload Samples. Note that in this case this will clear any filters that were set.
Sensitive information and Discover data
Sentences where users provide sensitive information may appear in your Discover data. This is especially true if your NLU model includes entities collecting sensitive information. For example, if your model includes an entity for collecting home addresses, Discover data will likely include sentences where users provided their home address.
NLU modeling and sensitive information
If you are collecting Discover data, you will already have defined, built, and deployed an NLU model. Recall that when designing and developing your project, you should already have:
- Identified anywhere you would reasonably expect to ask for or receive sensitive data and what types of data
- Created entities to collect and identify that information
- Flagged those entities as sensitive
- Provided realistic and complete training examples including (synthetic) sensitive data and annotated accordingly
With this done, your trained NLU model ideally should:
- Recognize the sensitive data in user input utterences
- Redact the sensitive data in call logs in records of both raw user inputs and NLU interpretations of those inputs.
Handling unredacted sensitive data in Discover
However, no system is perfect. Sometimes you will get false negatives, and sensitive data will show up unredacted in the call logs. If this happens, the same data can end up pulled into Discover data. You need to pay attention for this when reviewing Discover data and take actions to handle it when you see it.
If you spot sensitive data unredacted in Discover data, you should do the following if you want to add the sentences to the training set:
- Identify the Discover data samples containing unredacted sensitive data.
- Annotate the sample with the correct intent setting (specific intent, NO_INTENT, or UNASSIGNED_SAMPLES) and entity (if the data relates to an existing entity)
- Replace the sensitive real data with synthetic data.
- Make a note of the sentence so that you can investigate in the logs as needed.
- If you encounter sensitive data you did not previously account for in your ontology, you can define a new entity and annotate the sentence accordingly after importing from Discover.
Iterate your model
Using the insights gained from the Discover tab, you can refine your training data set, build and redeploy your updated model, and finally view the data from your refined model on the Discover tab. Rinse and repeat! You can improve your model (and your application) over time using an iterative feedback loop.
Related topics
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.