Runtime app development
The gRPC protocol for NLU lets you create a client application for requesting and receiving semantic interpretation from input text. This topic describes how to implement the basic functionality of NLU in the context of a Python application. For the complete application, see Sample Python runtime client.
The essential tasks are shown in the following high-level sequence flow:
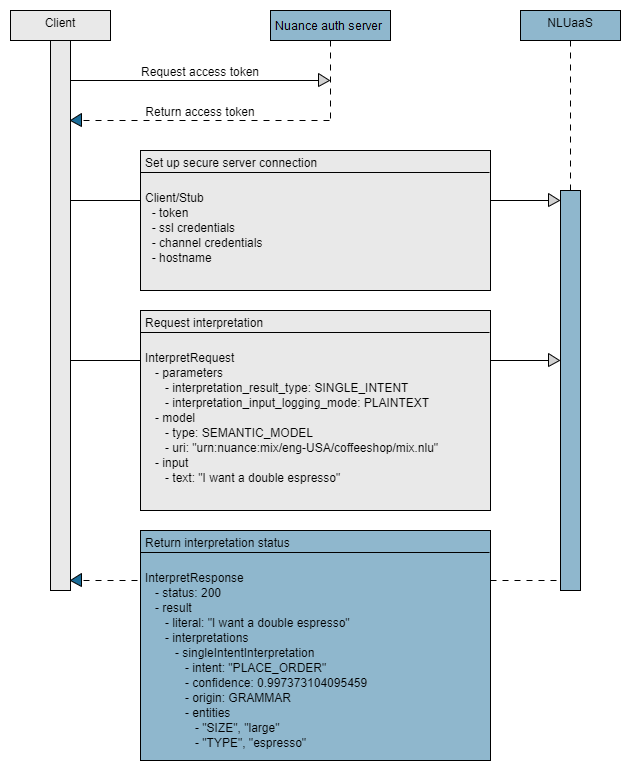
Step 1: Generate token
Nuance Mix uses the OAuth 2.0 protocol for authorization. Your client application must provide an access token to be able to access the NLU runtime service. The token expires after a period of time so must be regenerated periodically. Nuance recommends reusing the access token until it expires.
Note:
The application may be limited to a certain maximum number of active access tokens and the authorization service is subject to rate limits, as described in Rate limits. If limits are exceeded, the application may be refused a new access token and a 429 TOO_MANY_REQUESTS error code may be returned. Make sure to reuse access tokens until they expire to avoid these errors.Your client application uses the client ID and secret from the Mix Dashboard (see Prerequisites from Mix) to generate an access token from the Nuance authorization server, available at the following URL:
https://auth.crt.nuance.com/oauth2/token
The token may be generated in two ways
- As part of the client application: The client application receives the Client ID and secret and the OAuth URL and generates and manages the token itself.
- As part of a run script file: The run script generates the token and then passes it to the client application.
The sample Python app examples provide Linux bash scripts and Windows batch scripts supporting each of these two scenarios. Note that the first approach of letting the client application handle token generation and management is prefered, as it allows for better reuse of the token for the duration of its lifetime.
Note that the same token should be reused until it expires rather than requested for each interpretation. Generating a new token every time adds to latency. Also, token requests have more strict rate limits in place.
Step 2: Import functions
In your client application, import all functions from the client stubs that you generated in gRPC setup.
from nuance.nlu.v1.runtime_pb2 import *
from nuance.nlu.v1.runtime_pb2_grpc import *
from nuance.nlu.v1.result_pb2 import *
Do not edit these stub files.
Step 3: Authorize and connect
You create a secure gRPC channel and authorize your application to the NLU service by providing the URL of the hosted NLU service and an access token.
In the Python example, the URL of the NLU service is passed to the application as a command-line argument. The URL is passed as the first argument: nlu.api.nuance.com:443.
def create_channel(args):
channel = None
call_credentials = None
if args.token:
log.debug("Adding CallCredentials with token %s" % args.token)
call_credentials = grpc.access_token_call_credentials(args.token)
log.debug("Creating secure gRPC channel")
channel_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(channel_credentials, call_credentials)
channel = grpc.secure_channel(args.serverUrl, credentials=channel_credentials)
return channel
Step 4: Call Runtime client stub
With a communication channel established, the app calls a client stub function or class, which makes use of the channel. This stub is based on the main service name and is defined in the generated client files. In Python it is named RuntimeStub.
with create_channel(args) as channel:
stub = RuntimeStub(channel)
response = stub.Interpret(construct_interpret_request(args))
print(MessageToJson(response))
print("Done")
Step 5: Configure interpret request
An interpretation request includes InterpretationParameters that define the type of interpretation you want. Consult your generated stubs for the precise parameter names. Some parameters are:
- Interpretation result type: Single or multi-intent interpretation.
- Logging mode: Format for log input.
It also includes resources referenced to help with the interpretation. This includes:
- Model (mandatory): The semantic model created in Mix.nlu.
- Resources: A list of wordsets, either inline or compiled.
The input to interpret must also be provided, either plain text or the result from a call to ASRaaS.
For example:
# Single intent, plain text logging
params = InterpretationParameters(interpretation_result_type=EnumInterpretationResultType.SINGLE_INTENT, interpretation_input_logging_mode=EnumInterpretationInputLoggingMode.PLAINTEXT)
# Reference the model via the app config
model = ResourceReference(type=EnumResourceType.SEMANTIC_MODEL, uri=args.modelUrn)
# Describe the text to perform interpretation on
input = InterpretationInput(text=args.textInput)
# Reference compiled wordset if included as an input
if args.wordsetUrn:
wordset_reference = ResourceReference(type=EnumResourceType.COMPILED_WORDSET, uri = args.wordsetUrn)
resource = InterpretationResource(external_reference = wordset_reference)
resources = [resource]
# Build the request
interpret_req = InterpretRequest(parameters=params, model=model, resources=resources, input=input)
else:
# Build the request
interpret_req = InterpretRequest(parameters=params, model=model, input=input)
For more details, see InterpretRequest.
Step 6: Request interpretation
After calling the client stub and configuring the InterpretRequest you can send the InterpretRequest.
def main():
args = parse_args()
log_level = logging.DEBUG
logging.basicConfig(
format='%(lineno)d %(asctime)s %(levelname)-5s: %(message)s', level=log_level)
with create_channel(args) as channel:
stub = RuntimeStub(channel)
response = stub.Interpret(construct_interpret_request(args))
print(MessageToJson(response))
print("Done")
Step 7: Process results
Finally the app returns the results received from the NLU engine. These applications format the interpretation result as a JSON object, similar to the Try panel in Mix.nlu.
def process_result(response):
print(MessageToJson(response))
For details about the structure of the result, see InterpretResult.
Related topics
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.