Regex-based entities
An entity with regex-based collection method defines a set of values using regular expressions. For example, product or order values are typically alphanumeric sequences with a regular format, such as gro-456 or ABC 967. Both of these examples, and many more codes with the same general pattern, can be described with the regex pattern:
[A-Za-z]{3}\s?-?\s?[0-9]{3}
Similarly, you might use entities with regex-based collection to match account numbers, postal (zip) codes, confirmation codes, PINs, or driver’s license numbers, and other pattern-based formats.
Creating regex-based entities
To use a regular expression to validate the value of an entity (for example, an order number as shown below), enter the expression as valid JavaScript.
In this example the user is creating a regex-based entity called ORDER_NUMBER, which will match order numbers in the form gro-456, COF-123, sla 889, and so on (three characters + an optional hyphen and/or space + three digits).
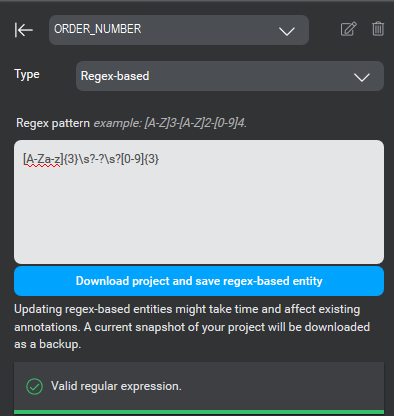
To save the pattern, click Download project and save regex-based entity.
Before the entity-type is created (or modified), Mix.nlu exports your existing NLU model to a ZIP file containing a TRSX file so that you have a backup. Creating (or modifying) a regex-based entity requires your NLU model to be re-tokenized, which may take some time and impact your existing annotations. You receive a message when the entity is saved successfully.
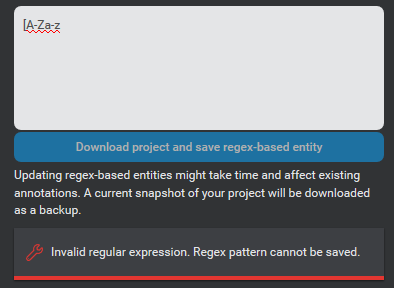
Mix.nlu validates the search pattern as you enter it and alerts you if it is invalid. Invalid expressions (including empty values) are not saved.
Notes and cautions
Note the following points when creating regular expressions in regex-based entities:
- The escape character is a single backslash (\).
- Include [A-Za-z] in all regexes to cover both upper and lowercase characters. Sentences may be changed to lowercase during normalization, for example, PROD9997 is changed to prod9997, so your regular expressions should be case insensitive to cover these variants in case.
- A regex definition may not exceed 255 characters.
- Mix.nlu supports a single regex definition per entity.
- You can change a regex-based entity to any other entity type. However, the definition is not saved. Make a note of complex patterns should you wish to use (or recreate) them again.
- Dynamic regex entities are not supported.
Regex collection type and speech inputs
Self-hosted environments: Matching speech recognition results to regex collection type entities is currently only supported for the hosted engine pack. This feature is not currently supported for version 2.x Engine pack releases for Speech Suite deployments nor for version 3.x Engine pack releases for self-hosted Mix deployments.
The NLUaaS Runtime API can take in both text and ASRaaS speech recognition results as input for interpretation.
For Nuance-hosted NLUaaS, regex collection type entities designed to detect numeric and alphanumeric patterns can in some cases also work for speech recognition results. This works when the formatted text version of the ASRaaS result successfully renders the recognition text in the way it would typically be written. Note that the ASRaaS text formatting is oriented toward certain common patterns like dates, times, phone numbers, and so on. Performance will depend on the specific language data pack installed and may require some manual configuration of the ASRaaS formatting scheme for best results.
If the ASRaaS formatting is not rendering the pattern as expected for a specific case, a Rule-based entity collection type using a GrXML grammar may be a better solution.
Capture groups
Be careful when using parentheses in a regular expression, for example to quantify a sub-pattern with +, *, ?, or {m,n}. Enclosing in parentheses creates a capture group. In general programming, matching a regex pattern with capture groups on a string returns both the full pattern, and the individual capture groups, in order, packaged as an array.
With Mix.nlu specifically, however, an entity expects a single value. When you use a regex with capture groups, Mix.nlu will return the result from the first capture group only rather than the full pattern. This is to allow extra flexibility for developers; for example if you want to recognize a date pattern, but only need the month to fulfill the user’s intent. If you need to use a parenthetical group, but want the full pattern match as the value returned for the entity, there are two options:
- Wrap the entire regex pattern in parentheses.
- Use non-capturing groups with (?: ) instead.
Anchors
Avoid using a caret (^) to denote the beginning of a regular expression, or a dollar sign ($) to denote the end, as doing so will cause the NLU engine to expect the expression at the beginning, or end, of a sentence. Consider this phone number regex-based entity (any phone number of format 123-456-7890):
(?:\+\d{1,2}\s)?\(?\d{3}\)?[\s.-]\d{3}[\s.-]\d{4}$will be matched successfully, if the phone number occurs at the end of the sentence (note $ at end of expression) such as in the case of “My telephone number is 123-456-7890”. It will not, however, match “123-456-7890 is my phone number.”^(?:\+\d{1,2}\s)?\(?\d{3}\)?[\s.-]\d{3}[\s.-]\d{4}will match “123-456-7890 is my phone number” but not “My telephone number is 123-456-7890”^(?:\+\d{1,2}\s)?\(?\d{3}\)?[\s.-]\d{3}[\s.-]\d{4}$will match “123-456-7890” but not the above.(?:\+\d{1,2}\s)?\(?\d{3}\)?[\s.-]\d{3}[\s.-]\d{4}will match all of the above scenarios.
Annotating with regex-based entities
Annotating with regex-based entities means identifying the tokens to be captured by the regex-defined value. At runtime the model tries to match user words with the regular expression.
For example:
What's the status of order [ORDER_NUMBER]COF-123[/]
Note:
The annotation is not tested by Mix.nlu to ensure that it matches the regular expression you defined. Check the value of the regex-based entity carefully to ensure that your annotations match the definition.Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.