Evaluating NLU accuracy
This topic provides best practices around generating test sets and evaluating NLU accuracy at a dataset and intent level.
For information on testing individual utterances using Mix.nlu, see Test your model.
Make sure the test data is of the highest possible quality
In this context, “high quality” means two things:
- The utterances in the test data are maximally similar to what users would actually say to the production system (ideally, the test data is made up of utterances that users have already spoken to the production system). In general, the possible sources of test data, in descending order of quality, are as follows:
- Usage data from a deployed production system
- Usage data from a pre-production version of the system (for example, a company-internal beta)
- Data collection data (for example, collected by asking people answer survey questions)
- Artificially generated data (for example, by defining grammar templates such as “I’d like a $SIZE $DRINK please” and expanding these with appropriate dictionaries for each template variable)
- The test set utterances are annotated correctly.
Generate both test sets and validation sets
When developing NLU models, you will need two separate types of data sets:
- A training set that is used to train the parameters on each refinement of the model structure.
- An evaluation set that is at least partially distinct data from the training process and used to check the ability of the trained model to generalize to real data.
Whenever possible, it is best practice to divide evaluation data into two distinct sets:
- The validation set serves as a check of the performance of the current refinement of the model. The model can be improved based on detailed error analysis of the results on the validation set (see Improving NLU accuracy).
- The test set is only used to test the final selected model following an iterative process of refinement involving cycles of adjusting the model structure, training on the training set, and evaluating using the validation set. The test set is sometimes called a “blind” set because the NLU developers may not look at its content. This keeps the data similar to utterances that users will speak to the production system in that what will come is not known ahead of time. To protect the test set as a final test of the model, the test set data may not be used for any error analysis or for improving the training data.
Once you have annotated usage data, you typically want to use it for both training and testing. Typically, the amount of annotated usage data you have will increase over time. Initially, it’s most important to have test sets so that you can properly assess the accuracy of your model. As you get additional data, you can also start adding it to your training data.
Once you have a lot of data, a fairly standard and traditional partitioning of data is an entirely random 80%/10%/10% (or 70%/20%/10%) train/validate/test split, though other partitions, such as 60%/20%/20%, are also common—it largely depends on whether the resulting test sets are large enough (see below). Note that it is fine, and indeed expected, that different instances of the same utterance will sometimes fall into different partitions.
Note that the above recommended partition splits are for production usage data only. When you are training an initial model based on artificial data, you need enough test data (see below) in order for your results to be statistically significant, but it doesn’t make sense to create a huge amount of artificial training data for an initial model. In the case of an initial model prior to production, the split may end up looking more like 33%/33%/33%.
Some data management is helpful to segregate the test data from the training and test data, and from the model development process in general. Ideally, the person handling the splitting of the data into train/validate/test and the testing of the final model should be someone outside the team developing the model.
Make sure you have enough test data
In order for test results to be statistically significant, test sets must be large enough. Ideal test set size depends on many factors. As a very rough rule of thumb, a good test set should contain at least 20 utterances for each distinct intent and entity in the ontology. The test set for an ontology with two intents, where the first intent has no entities and the second intent has three entities, should contain at least 100 utterances (2 intents + 3 entities = 5; 5 * 20 utterances = 100). Your validation and blind sets should each be at least this large.
Make sure the distribution of your test data is appropriate
The validation and test sets should be drawn from the same distribution as the training data—they should come from the same source (whether that is usage data, collected data, or developer-generated data), and the partition of the data into train/validation/test should be completely random.
Note that if the validation and test sets are drawn from the same distribution as the training data, then there will be some overlap between these sets (that is, some utterances will be found in multiple sets).
Use the Mix Testing Tool
Nuance provides a tool called the Mix Testing Tool for running a test set against a deployed NLU model and measuring the accuracy of the set on different metrics. For more details, speak to your Nuance representative.
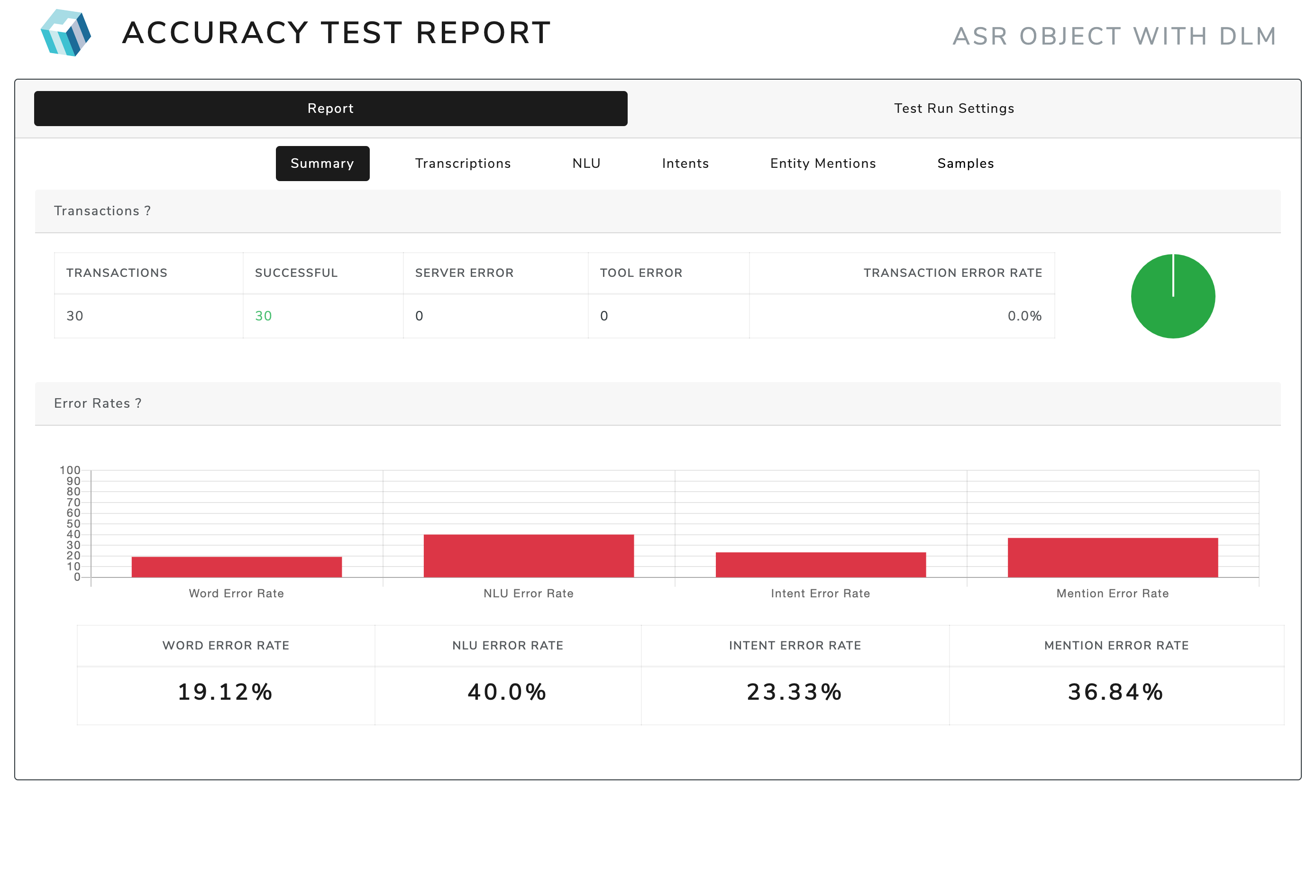
To the side, see of the output of MTT.
- Under the ‘Summary’ tab in the ‘Error Rates’ pane, you can see the NLU Error Rate, which corresponds to the full sentence accuracy, the Intent Error Rate which corresponds to the intent accuracy, and the Slot Error Rate which corresponds to the entity accuracy.
- If you click on the ‘Slots’ tab, you can see accuracy/error rates for each slot (entity) individually, across all intents, as well as per-intent slot error rate/accuracy.
The best overall metric of NLU accuracy is full sentence accuracy, which is the percentage of utterances for which the predicted intent and all predicted entity types and values exactly match the reference, or ground truth, annotation.
Use adjudication rules when appropriate
Adjudication rules refer to rules that are applied during evaluation to allow non-exact matches to count as accurate predictions. In some cases, there may be entities or intents that you want to have considered as equivalent, such that either counts as correct for an accuracy calculation. For example, some applications may not care whether an utterance is classified as a custom OUT_OF_DOMAIN intent or the built-in NO_MATCH intent. Meaning-text theory (MTT) supports adding adjudication rules for considering different intents or entities to be equivalent, as well as for ignoring entities entirely.
Don’t cherry pick individual utterances
When analyzing NLU results, don’t cherry pick individual failing utterances from your validation sets (you can’t look at any utterances from your test sets, so there should be no opportunity for cherry picking). No NLU model is perfect, so it will always be possible to find individual utterances for which the model predicts the wrong interpretation. However, individual failing utterances are not statistically significant, and therefore can’t be used to draw (negative) conclusions about the overall accuracy of the model. Overall accuracy must always be judged on entire test sets that are constructed according to best practices.
If there are individual utterances that you know ahead of time must get a particular result, then add these to the training data instead. They can also be added to a regression test set to confirm that they are getting the right interpretation. However, doing this is unrelated to accuracy testing.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.